728x90
반응형
Large Language Models (LLMs), 대규모 언어 모델
대규모 언어 모델(LLM, Large Language Models)은 방대한 양의 텍스트를 처리하고 정확한 결과를 생성하는 기능으로 인해 자연어 처리(NLP) 세계에서 관심을 끌고 있습니다. 이러한 모델은 수억에서 수십억 단어가 포함된 대규모 데이터 세트에서 학습됩니다. 알려진 바와 같이 LLM은 대규모 데이터 세트를 통해 이동하고 단어 수준에서 패턴을 인식하는 Transformer 아키텍처를 포함한 복잡한 알고리즘에 의존합니다. 이 데이터는 모델이 자연어와 컨텍스트에서 사용되는 방식을 더 잘 이해하고 텍스트 생성, 텍스트 분류 등과 관련된 예측을 수행하는 데 도움이 됩니다.
Large Language Model 이란
a class of deep learning models designed to process and understand vast amounts of natural language data
방대한 양의 자연어 데이터를 처리하고 이해하도록 설계된 딥 러닝 모델 클래스
대규모 언어 모델(LLM)은 언어와 함께 작동하는 AI 시스템 유형입니다. LLM은 언어 모델링, 즉 단순하지만 유용한 디지털 표현을 만드는 것을 목표로 합니다. 용어의 '큰' 부분은 더 많은 매개변수를 사용하여 언어 모델을 학습하는 추세를 설명합니다.
LLM의 일반적인 예로는 OpenAI의 GPT-4, Google의 PaLM 및 Meta의 LLaMA가 있습니다. 특정 제품(예: OpenAI의 ChatGPT 또는 Google의 Bard)을 LLM 자체로 참조할지 아니면 기본 LLM에서 제공한다고 말할지 모호합니다.
용어로 LLM은 종종 AI 실무자가 언어와 함께 작동하는 시스템을 지칭하는 데 사용됩니다.
GPT(Generative Pre-trained Transformer)는 이러한 대규모 언어 모델 중 하나입니다.

Pretrained
이 모델은 초기에 많은 양의 텍스트 데이터에 대해 학습됩니다.
Fine-tuning
이 모델은 특정 생성 작업에 맞게 fine-tuning됩니다.
Transformer
자연어 데이터를 처리하고 분석하는 데 사용되는 머신 러닝 아키텍처 유형입니다.
Encoders and decoders
인코더와 디코더는 텍스트와 같은 데이터 시퀀스를 처리하고 생성하는 데 사용되는 트랜스포머 아키텍처의 구성 요소입니다.
인코더는 문장과 같은 일련의 입력 데이터를 가져와서 일련의 인코딩된 표현으로 변환합니다. 각 표현은 원본 입력 데이터에 대한 정보를 캡처하지만 추상화 수준은 다릅니다. 최종 인코딩된 표현은 일반적으로 입력 시퀀스를 요약하는 벡터입니다.
반면에 디코더는 인코딩된 표현을 가져와 원래 문장을 다른 언어로 번역하는 것과 같은 새로운 데이터 시퀀스를 생성하는 데 사용합니다.
디코더는 인코딩된 표현과 지금까지 생성된 토큰을 기반으로 시퀀스의 다음 토큰을 예측하여 이를 수행합니다.
다음은 인코더와 디코더가 함께 작동하여 문장을 영어에서 프랑스어로 번역하는 방법의 예입니다.
문장 입력: "The cat sat on the mat."
인코딩된 표현: [0.2, 0.5, -0.1, 0.4, ...]
대상 언어: 프랑스어
디코더 출력: 'Le chat s'est assis sur le tapis.'
이 예에서 인코더는 영어 문장을 입력으로 사용하고 저차원 공간에서 문장의 의미를 캡처하는 인코딩된 표현을 생성합니다. 그런 다음 디코더는 이 인코딩된 표현을 사용하여 대상 언어인 프랑스어로 새로운 토큰 시퀀스를 생성합니다. 최종 출력은 원래 문장과 동일한 의미를 캡처하지만 다른 언어로 번역된 문장입니다.
대규모 언어 모델은 (주로) 텍스트 생성 작업을 해결하여 보다 효과적인 human-machine 소통을 가능하게 하는 머신 러닝 모델로 정의할 수 있습니다. 이것이 바로 LLM이 방대한 양의 텍스트 데이터를 처리 및 이해하고 문장에서 단어 간의 패턴과 관계를 학습해야 하는 이유입니다. GPT-4 및 ChatGPT는 다양한 작업을 위한 텍스트 생성에서 뛰어난 성능을 보여주는 고급 LLM입니다.
LLM은 신경망 아키텍처, 특히 transformer 아키텍처를 기반으로 구축되어 대규모 텍스트 데이터 세트에서 복잡한 언어 패턴과 단어 또는 구문 간의 관계를 캡처할 수 있습니다. 사실 LLM은 transformer의 변형으로도 이해할 수 있습니다.
Transformer 아키텍처는 cross-attention 및 self-attention와 같은 메커니즘에 의존하며, 이를 통해 모델은 주어진 맥락에서 서로 다른 단어나 구의 중요성을 평가하여 텍스트의 단어 간의 관계를 이해할 수 있습니다.
cross-attention 메커니즘을 통해 모델은 생성된 텍스트에서 다음 단어를 정확하게 예측하는 데 필요한 입력 텍스트의 중요한 부분을 식별할 수 있습니다. 반대로 self-attention 메커니즘은 처리 중에 입력의 다양한 섹션에 선택적으로 주의를 기울이는 모델의 기능을 말합니다.
transformer 아키텍처는 Vaswani 등의 논문 'Attention Is All You Need'에서 소개된 encoder-decoder architecture를 기반으로 하는 자연어 처리 작업을 위한 신경망 모델을 나타냅니다.
트랜스포머 아키텍처의 핵심 구성 요소는 모델이 각 위치에 대한 표현을 계산하기 위해 입력 시퀀스의 다른 부분에 주의를 기울일 수 있게 해주는 셀프 어텐션 메커니즘입니다. 트랜스포머는 인코더 네트워크와 디코더 네트워크의 두 가지 주요 구성 요소로 구성됩니다. 인코더 네트워크는 입력 시퀀스를 사용하여 숨겨진 상태 시퀀스를 생성하는 반면, 디코더 네트워크는 대상 시퀀스를 사용하고 인코더의 출력을 사용하여 예측 시퀀스를 생성합니다. 인코더와 디코더는 모두 여러 계층의 self-attention 및 feedforward 신경망으로 구성됩니다.
[NLP] Transformer Model
Transformer Model Attention is All You Need라는 논문을 통해 처음 발표(Vaswani et al.. 2017) Input text를 입력받아, 기본적으로 Attention 매커니즘을 통해 인코딩, 디코딩하는 방식의 모델 병렬화가 가능하고 학습
yumdata.tistory.com
Different types of LLMs
Autoregressive Language Models
[NLP] GPT
GPT(Generative Pre-trained Transformer) OpenAI에서 Transformer의 Decoder를 활용해 발표한 Pretrained 언어 모델 GPT-1 : 2018년 발표 GPT-2 : 2019년 2월 발표, 제한된 데모버전만 공개 GPT-3 : 2020년 발표, 유료 Pretrained Langu
yumdata.tistory.com
자동회귀(Autoregressive) 모델은 이전 단어가 주어진 시퀀스에서 다음 단어를 예측하여 텍스트를 생성합니다.
주어진 맥락에서 훈련 데이터 세트의 각 단어의 가능성을 최대화하도록 훈련됩니다. 자동 회귀 언어 모델의 가장 잘 알려진 예는 OpenAI의 GPT(Generative Pre-trained Transformer) 시리즈이며 GPT-4는 가장 최신의 가장 강력한 모델입니다.
Autoencoding Language Models
[NLP] BERT
BERT(Bidirectional Encoder Representations for Transformers) Pre-training of Deep Bidirectional Transformers for Language Understanding 2018년 10월 논문이 공개된 구글의 새로운 Language Representation Model 모든 자연어 처리 분야에서
yumdata.tistory.com
자동 인코딩 모델은 마스크되거나 손상된 버전에서 원래 입력을 재구성하여 입력 텍스트의 고정 크기 벡터 표현(임베딩이라고도 함)을 생성하는 방법을 학습합니다. 주변 컨텍스트를 활용하여 입력 텍스트에서 누락되거나 가려진 단어를 예측하도록 훈련됩니다.
Google에서 개발한 BERT(Bidirectional Encoder Representations from Transformers)는 가장 유명한 자동 인코딩 언어 모델 중 하나입니다. 감정 분석, 명명된 엔터티 인식 및 질문 답변과 같은 다양한 NLP 작업에 맞게 fine-tuning 할 수 있습니다.
Combination of autoencoding and autoregressive
T5(Text-to-Text Transfer Transformer)
[NLP][Language Model] T5(Text-to-Text Transfer Transformer)
Transformer 모델의 성능 향상을 위한 시도 1. 어떻게 더 많이, 더 잘 훈련시켜서 성능을 향상시킬 수 있을까? pre-training objective 변형, 모델 변경 등 연구 난이도가 훨씬 높고 computing resource도 많이 필
yumdata.tistory.com
LLMs Use Case Scenarios
전통적인 NLP 알고리즘은 일반적으로 단어의 즉각적인 맥락만 보는 반면 LLM은 맥락을 더 잘 이해하기 위해 많은 양의 텍스트를 고려합니다. 다음은 텍스트 생성 및 텍스트 완성을 위한 자동 회귀 및 자동 인코딩 대규모 언어 모델의 사용을 보여주는 두 가지 예제 시나리오입니다.
자기회귀 모델이 어떻게 작동하는지 예를 들어 보겠습니다. 앞에서 배운 것처럼 GPT와 같은 자동 회귀 모델은 주어진 입력 프롬프트를 기반으로 일관되고 문맥적으로 관련 있는 문장을 생성합니다.
자동 회귀 모델에 대한 입력이 다음과 같다고 가정해 보겠습니다.
“Introducing new smartphone, the UltraPhone 3000, which is designed to”
생성된 텍스트는 다음과 같습니다.
“redefine your mobile experience with its cutting-edge technology and unparalleled performance.”
자동 인코딩 모델이 작동하는 방식에 대한 또 다른 예를 들어 보겠습니다. 앞에서 배운 것처럼 BERT와 같은 자동 인코딩 모델은 문장에서 누락되거나 가려진 단어를 채우는 데 사용되어 의미론적으로 의미 있고 완전한 문장을 생성합니다.
자동 인코딩 모델에 대한 입력이 다음과 같다고 가정해 보겠습니다.
The latest superhero movie had an _______ storyline, but the visual effects were _______.
완성된 텍스트는 다음과 같습니다.
The latest superhero movie had an decent storyline, but the visual effects were mind-blowing.
Key Building Blocks
LLM(Large Language Models)은 자연어 데이터를 효율적으로 처리하고 이해할 수 있게 해주는 몇 가지 주요 빌딩 블록으로 구성됩니다.
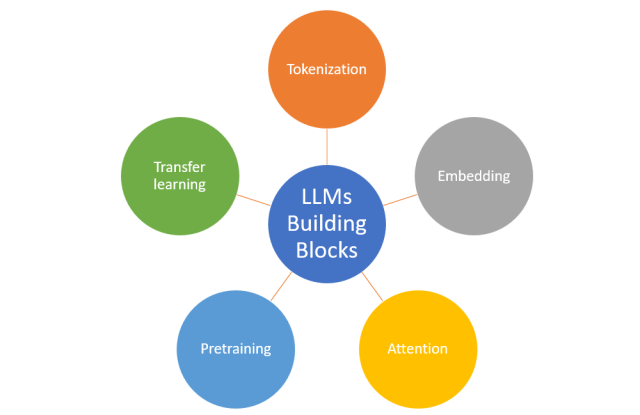
Tokenization
토큰화는 일련의 텍스트를 모델이 이해할 수 있는 개별 단어, 하위 단어 또는 토큰으로 변환하는 프로세스입니다.
LLM에서 토큰화는 일반적으로 BPE(Byte Pair Encoding) 또는 WordPiece와 같은 하위 단어 알고리즘을 사용하여 수행되며, 이는 텍스트를 빈도가 높은 단어와 희귀한 단어를 모두 캡처하는 더 작은 단위로 분할합니다. 이 접근 방식은 모든 텍스트 시퀀스를 나타내는 기능을 유지하면서 모델의 어휘 크기를 제한하는 데 도움이 됩니다.
Embedding
임베딩은 고차원 공간에서 의미론적 의미를 캡처하는 단어 또는 토큰의 연속적인 벡터 표현입니다. 이를 통해 모델은 개별 토큰을 신경망에서 처리할 수 있는 형식으로 변환할 수 있습니다. LLM에서 임베딩은 훈련 프로세스 중에 학습되며 결과 벡터 표현은 동의어 또는 유추와 같은 단어 간의 복잡한 관계를 캡처할 수 있습니다.
Attention
LLM의 어텐션 메커니즘, 특히 트랜스포머에 사용되는 셀프 어텐션 메커니즘을 통해 모델은 주어진 컨텍스트에서 다른 단어나 구문의 중요성을 평가할 수 있습니다. 입력 시퀀스의 토큰에 서로 다른 가중치를 할당함으로써 모델은 덜 중요한 세부 정보를 무시하면서 가장 관련성이 높은 정보에 집중할 수 있습니다. 입력의 특정 부분에 선택적으로 초점을 맞추는 이 기능은 장기적인 종속성을 캡처하고 자연어의 뉘앙스를 이해하는 데 중요합니다.
Pre-training
Pre-training은 특정 작업을 위해 fine-tuning하기 전에 일반적으로 unsupervised 또는 self-supervised되는 대규모 데이터 세트에서 LLM을 훈련하는 프로세스입니다.
사전 학습 중에 모델은 일반적인 언어 패턴, 단어 간의 관계 및 기타 기본 지식을 학습합니다. 이 프로세스는 더 작은 작업별 데이터 세트를 사용하여 fine-tuning할 수 있는 사전 훈련된 모델을 생성하여 다양한 NLP 작업에서 높은 성능을 달성하는 데 필요한 레이블이 지정된 데이터의 양과 훈련 시간을 크게 줄입니다.
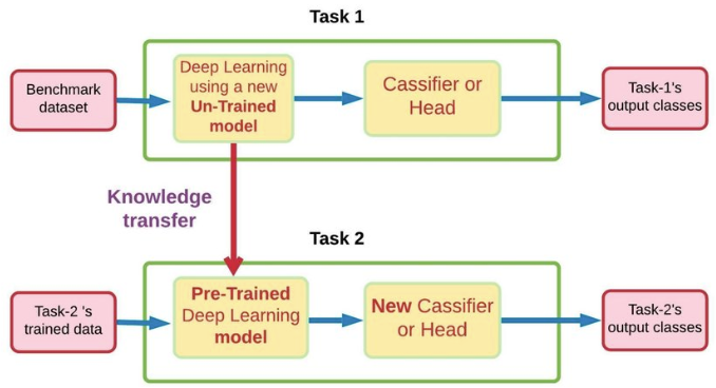
Transfer Learning
특정 태스크를 학습한 모델을 다른 태스크 수행에 재 사용하는 기법
Transfer Learning은 pre-training 중에 얻은 지식을 활용하여 새로운 관련 작업에 적용하는 기술입니다.
LLM의 맥락에서 transfer learning에는 해당 작업에서 높은 성능을 달성하기 위해 더 작은 작업별 데이터 세트에서 사전 훈련된 모델을 fine-tuning하는 작업이 포함됩니다. transfer learning의 이점은 모델이 사전 훈련 중에 학습된 방대한 양의 일반 언어 지식으로부터 이점을 얻을 수 있도록 하여 레이블이 지정된 대규모 데이터 세트와 각각의 새로운 작업에 대한 광범위한 훈련의 필요성을 줄인다는 것입니다.
Examples of Large Language Models
[Large Language Model] FLAN-T5
[Large Language Model] GPT-NeoX-20B
[Large Language Model] mT5-xxl
[Large Language Model] Flan-UL2
[Large Language Model] BLOOMZ & mT0
결론
대규모 언어 모델은 인간의 개입을 최소화하면서 자연어 데이터를 빠르고 정확하게 처리하기 위한 강력한 도구입니다. 이러한 모델은 텍스트 생성, 감정 분석, 질문 응답 시스템, 자동 요약, 기계 번역, 문서 분류 등과 같은 다양한 작업에 사용할 수 있습니다. 방대한 양의 텍스트 데이터를 빠르고 정확하게 처리할 수 있는 LLM의 능력 덕분에 LLM은 다양한 산업 분야의 다양한 응용 프로그램을 위한 귀중한 도구가 되었습니다. NLP 연구자와 전문가는 빠르게 진화하는 이 분야에서 앞서 나가려면 대규모 언어 모델에 확실히 익숙해져야 합니다. 대체로 대규모 언어 모델은 기계가 자연어를 더 잘 이해하고 텍스트를 처리할 때 더 정확한 결과를 생성할 수 있도록 하기 때문에 NLP에서 중요한 역할을 합니다. 이러한 모델은 딥 러닝 신경망과 같은 AI 기술을 활용하여 방대한 양의 데이터를 빠르게 분석하고 다양한 산업 분야의 다양한 응용 프로그램에 사용할 수 있는 매우 정확한 결과를 제공할 수 있습니다.
White Papers for Learning Large Language Models
- Neural Machine Translation by Jointly Learning to Align and Translate (2014) by Bahdanau, Cho, and Bengio, https://arxiv.org/abs/1409.0473
- Attention Is All You Need (2017) by Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin, https://arxiv.org/abs/1706.03762
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) by Devlin, Chang, Lee, and Toutanova, https://arxiv.org/abs/1810.04805
- Improving Language Understanding by Generative Pre-Training (2018) by Radford and Narasimhan, https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019), by Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, and Zettlemoyer, https://arxiv.org/abs/1910.13461
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023) by Yang, Jin, Tang, Han, Feng, Jiang, Yin, and Hu, https://arxiv.org/abs/2304.13712
References
https://vitalflux.com/large-language-models-concepts-examples/
728x90
반응형
'Generative AI > Language Model' 카테고리의 다른 글
| [Large Language Model] LaMDA (0) | 2023.07.13 |
|---|---|
| [Large Language Model] ChatGPT (0) | 2023.07.13 |
| [Large Language Model] MPT-7B, MPT-7B-Instruct (0) | 2023.07.11 |
| [Large Language Model] GPT-NeoX-20B (0) | 2023.07.11 |
| [Large Language Model] mT5-xxl (0) | 2023.07.11 |