MPT-7B
https://huggingface.co/mosaicml/mpt-7b
mosaicml/mpt-7b · Hugging Face
MPT-7B MPT-7B is a decoder-style transformer pretrained from scratch on 1T tokens of English text and code. This model was trained by MosaicML. MPT-7B is part of the family of MosaicPretrainedTransformer (MPT) models, which use a modified transformer archi
huggingface.co
a decoder-style transformer pretrained from scratch on 1T tokens of English text and code
trained by MosaicML
MPT-7B는 MosaicPretrainedTransformer(MPT) 모델 제품군의 일부로 효율적인 훈련 및 추론에 최적화된 수정된 transformer 아키텍처를 사용합니다.
이러한 아키텍처 변경에는 위치 임베딩을 ALiBi(Attention with Linear Biases)로 대체하여 성능 최적화된 레이어 구현 및 컨텍스트 길이 제한 제거가 포함됩니다. 이러한 수정 덕분에 MPT 모델은 높은 처리량 효율성과 안정적인 수렴으로 훈련될 수 있습니다. MPT 모델은 또한 표준 HuggingFace 파이프라인과 NVIDIA의 FasterTransformer 모두에서 효율적으로 제공될 수 있습니다.
이 모델은 llm-foundry repository에서 찾을 수 있는 MosaicML LLM 코드베이스를 사용합니다. LLM pretraining, finetuning 및 추론(inference)을 위해 MosaicML platform에서 MosaicML의 NLP 팀에 의해 훈련되었습니다.
Training Data
Streaming Datasets
데이터는 MosaicML StreamingDataset 라이브러리를 사용하여 형식화되어 데이터를 객체 스토리지에 호스팅하고 훈련 중에 컴퓨팅 클러스터로 효율적으로 스트리밍합니다. StreamingDataset은 훈련을 시작하기 전에 전체 데이터 세트를 다운로드할 필요가 없으며 데이터 세트의 모든 지점에서 훈련을 즉시 재개할 수 있습니다.
Data Mix
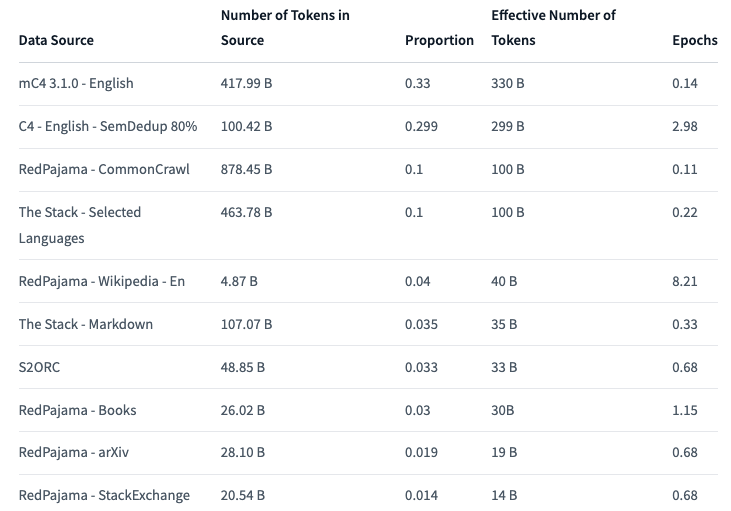
이 모델은 1T 토큰(배치 크기 1760 및 시퀀스 길이 2048)에 대해 훈련되었습니다. 다음 데이터 조합에 대해 교육을 받았습니다.
MPT-7B-Instruct
https://huggingface.co/mosaicml/mpt-7b-instruct
mosaicml/mpt-7b-instruct · Hugging Face
MPT-7B-Instruct MPT-7B-Instruct is a model for short-form instruction following. It is built by finetuning MPT-7B on a dataset derived from the Databricks Dolly-15k and the Anthropic Helpful and Harmless (HH-RLHF) datasets. This model was trained by Mosaic
huggingface.co
짧은 형태의 지시를 따르기 위한 모델.
Databricks Dolly-15k 및 Anthropic Helpful and Harmless (HH-RLHF) 데이터 세트에서 파생된 데이터 세트에서 MPT-7B를 finetuning하여 구축
'Generative AI > Language Model' 카테고리의 다른 글
| [Large Language Model] ChatGPT (0) | 2023.07.13 |
|---|---|
| Large Language Model (LLM) (0) | 2023.07.11 |
| [Large Language Model] GPT-NeoX-20B (0) | 2023.07.11 |
| [Large Language Model] mT5-xxl (0) | 2023.07.11 |
| [Large Language Model] Flan-UL2 (0) | 2023.07.11 |