Flan-UL2
https://huggingface.co/google/flan-ul2
google/flan-ul2 · Hugging Face
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the UL2 model released earlier last year. It was fine tuned using the "Flan" prompt tuning and dataset collection. You can use the convert_t5x_checkpoint_t
huggingface.co
Google, 20 billion parameters, downloadable from HuggingFace
An encoder-decoder model based on the T5 architecture and instruction-tuned using the Fine-tuned Language Net.
Flan-UL2는 인코더 디코더 모델이며 그 핵심은 Flan을 사용하여 훈련된 T5 model 의 강화된 버전입니다. Flan-T5의 '이전' 버전을 능가하는 성능을 보여준다. Flan-UL2는 Apache-2.0 라이선스를 보유하고 있으며 사용법 및 교육에 대한 세부 정보가 공개되었으므로 자체 호스팅 또는 fine-tuning 가능한 모델에 대한 선택입니다.
Flan-UL2의 200억 매개변수가 너무 많은 경우 5가지 크기로 제공되고 요구 사항에 더 적합할 수 있는 Flan-T5의 이전 반복을 고려하십시오.
2022년 초 출시된 UL2 모델과 동일한 구성을 사용합니다.
'Flan' 프롬프트 튜닝 및 데이터 세트 수집을 사용하여 fine-tuned되었습니다.
원래 UL2 모델은 512의 수용 필드로만 훈련되었으므로 N이 큰 N-shot 프롬프트에 적합하지 않았습니다.
Flan-UL2 체크포인트는 2048의 수용 필드를 사용하여 상황에 맞는 몇 번의 학습(few-shot in-context learning)에 더 유용합니다.
원래 UL2 모델에는 좋은 성능을 얻기 위해 다소 필수적인 모드 스위치 토큰도 있었습니다. 그러나 추론 또는 finetuning 중에 종종 약간의 변경이 필요하기 때문에 약간 번거롭습니다. 이 업데이트/변경에서는 Flan 명령 튜닝을 적용하기 전에 '모드 토큰'을 잊어버리기 위해 추가 100k 단계(작은 배치 포함)에 대해 UL2 20B를 계속 교육합니다. 이 Flan-UL2 체크포인트는 더 이상 모드 토큰이 필요하지 않습니다.
Introduction to UL2
https://huggingface.co/google/ul2
google/ul2 · Hugging Face
UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. UL2 uses Mixture-of-Denoisers (MoD), apre-training objective that combines diverse pre-training paradigms together. UL2 introduces a notion of mode
huggingface.co
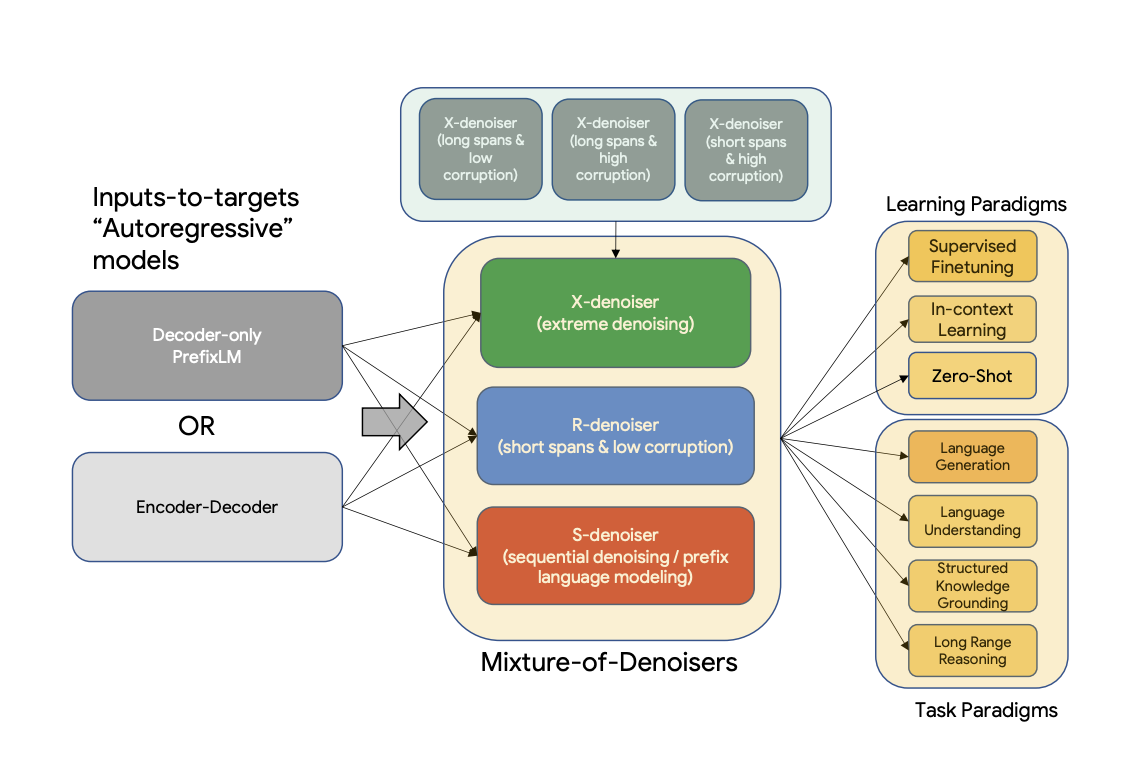
UL2는 데이터세트와 설정 전반에 걸쳐 보편적으로 효과적인 사전 학습 모델을 위한 통합 프레임워크입니다.
UL2는 다양한 사전 훈련 패러다임을 함께 결합하는 사전 훈련 목표인 MoD(Mixture-of-Denoisers)를 사용합니다.
UL2는 다운스트림 fine-tuning이 특정 사전 훈련 체계와 관련된 모드 전환 개념을 도입합니다.
개요
Paper: Unifying Language Learning Paradigms
Unifying Language Learning Paradigms
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training
arxiv.org
기존의 사전 훈련(pre-trained)된 모델은 일반적으로 특정 문제 클래스에 맞춰져 있습니다. 현재까지 올바른 아키텍처와 사전 훈련 설정이 무엇인지에 대한 합의가 아직 없는 것 같습니다.
이 백서에서는 데이터 세트와 설정 전반에 걸쳐 보편적으로 효과적인 사전 학습 모델을 위한 통합 프레임워크를 제시합니다.
일반적으로 결합되는 두 가지 개념인 사전 교육 목표를 사용하여 architecture 원형을 분리하는 것으로 시작합니다.
다음으로, 우리는 NLP에서 자기 감독(self-supervision)을 위한 일반화되고 통합된 관점을 제시하고 서로 다른 사전 훈련 목표가 서로 캐스팅될 수 있는 방법과 서로 다른 목표 사이의 보간이 어떻게 효과적일 수 있는지 보여줍니다.
그런 다음 다양한 사전 훈련 패러다임을 함께 결합하는 사전 훈련 목표인 MoD(Mixture-of-Denoisers)를 제안합니다.
또한 다운스트림 fine-tuning이 특정 사전 훈련 체계와 관련된 모드 전환 개념을 도입합니다.
여러 사전 훈련 목표를 비교하기 위해 광범위한 제거 실험을 수행하고 여러 다양한 설정에서 T5 및/또는 GPT 유사 모델을 능가하여 Pareto-frontier를 추진한다는 것을 발견했습니다.
마지막으로 모델을 최대 200억 개의 매개변수로 확장하여 언어 생성(자동 및 인간 평가 사용), 언어 이해, 텍스트 분류, 질문 응답, 상식 추론, 긴 텍스트 추론에 이르기까지 50개의 잘 확립된 감독 NLP 작업에서 SOTA 성능을 달성합니다.
구조화된 지식 접지 및 정보 검색. 우리의 모델은 또한 문맥 학습에서 강력한 결과를 달성하여 제로샷 SuperGLUE에서 175B GPT-3을 능가하고 원샷 요약에서 T5-XXL의 성능을 세 배로 늘립니다.
Training
Flan-UL2
Flan-UL2 모델은 UL2 체크포인트를 사용하여 초기화한 후 Flan Prompting을 사용하여 추가로 학습했습니다. 이것은 원래 훈련 코퍼스가 C4라는 것을 의미합니다.
'Scaling Instruction-Finetuned language models(Chung et al.)'(때때로 Flan2 논문이라고도 함)에서 핵심 아이디어는 데이터 세트 모음에서 대규모 언어 모델을 교육하는 것입니다. 이러한 데이터 세트는 다양한 작업에서 일반화를 가능하게 하는 지침으로 표현됩니다. Flan은 주로 학업 과제에 대한 교육을 받았습니다. Flan2에서는 Flan으로 명령 조정된 200M에서 11B 매개변수 범위의 일련의 T5 모델을 출시했습니다.
Flan 데이터 세트는 'The Flan Collection: Designing Data and Methods for Effective Instruction Tuning'(Longpre et al.)에서도 오픈 소스로 제공되었습니다.
UL2 Pretraining
모델은 C4 말뭉치에서 사전 훈련됩니다.
사전 훈련을 위해 모델은 배치 크기 1024로 C4(2백만 단계)에서 총 1조 개의 토큰에 대해 훈련됩니다.
시퀀스 길이는 입력 및 대상에 대해 512/512로 설정됩니다. 드롭아웃은 사전 훈련 중에 0으로 설정됩니다. 사전 훈련에는 약 1조 개의 토큰에 대해 한 달이 약간 넘게 걸렸습니다. 이 모델에는 32개의 인코더 레이어와 32개의 디코더 레이어, dmodel은 4096, df는 16384가 있습니다. 각 헤드의 차원은 총 16개의 헤드에 대해 256입니다. 우리 모델은 8의 모델 병렬성을 사용합니다. 어휘 크기 32000의 T5와 동일한 문장 조각 토크나이저가 사용됩니다(T5 토크나이저에 대한 자세한 내용을 보려면 여기를 클릭하십시오).
UL-20B는 T5와 매우 유사하지만 다른 목적과 약간 다른 스케일링 노브로 훈련된 모델로 해석할 수 있습니다.
UL-20B는 Jax 및 T5X 인프라를 사용하여 훈련되었습니다.
Mixture of Denoisers
강력한 범용 모델은 사전 교육 중에 다양한 문제를 해결하기 위해 노출되어야 한다고 추측합니다.
pre-training이 self-supervision을 사용하여 수행된다는 점을 감안할 때 이러한 다양성이 모델의 목적에 주입되어야 한다고 주장합니다. 그렇지 않으면 모델이 long-coherent 텍스트 생성과 같은 특정 기능이 부족할 수 있습니다.

R-Denoiser
일반 잡음 제거는 T5에 도입된 표준 범위 손상으로, 범위 길이로 2~5개의 토큰 범위를 사용하여 입력 토큰의 약 15%를 마스킹합니다.
이 범위는 유창한 텍스트를 생성하는 방법을 배우는 대신 지식을 습득하는 데 짧고 잠재적으로 유용합니다.
S-Denoiser
입력에서 대상으로 작업을 프레이밍할 때 엄격한 순차적 순서를 관찰하는 노이즈 제거의 특정 사례, 즉 접두사 언어 모델링. 이를 위해 입력 시퀀스를 컨텍스트와 대상으로 토큰의 두 하위 시퀀스로 분할하여 대상이 미래 정보에 의존하지 않도록 합니다.
이는 컨텍스트 토큰보다 이전 위치의 대상 토큰이 있을 수 있는 표준 범위 손상과 다릅니다. Prefix-LM 설정과 유사하게 컨텍스트(접두사)는 양방향 수용 필드를 유지합니다. 메모리가 매우 짧거나 메모리가 없는 S-Denoising은 표준 인과 언어 모델링과 유사한 정신에 있습니다.
X-Denoiser
노이즈 제거의 극단적인 버전으로 모델이 입력의 상당 부분을 복구해야 하며 입력의 작거나 중간 부분이 주어집니다. 이것은 모델이 상대적으로 제한된 정보로 메모리에서 긴 대상을 생성해야 하는 상황을 시뮬레이션합니다. 이를 위해 입력 시퀀스의 약 50%가 마스킹되는 적극적인 노이즈 제거와 함께 예제를 포함하도록 선택합니다. 이는 스팬 길이 및/또는 손상률을 증가시키는 것입니다. 스팬이 길거나(예: ≥ 12 토큰) 부패율이 큰 경우(예: ≥ 30%) 사전 훈련 작업을 극단적인 것으로 간주합니다. X-denoising은 규칙적인 스팬 손상과 목표와 같은 언어 모델 사이의 보간에 의해 동기가 부여됩니다.
Fine-tuning
모델은 N이 일반적으로 50k에서 100k인 N 사전 훈련 단계 후에 지속적으로 fine-tuning되었습니다.
즉, 사전 교육의 각 Nk 단계 후에 모델이 각 다운스트림 작업에서 fine-tuning됩니다.
모델이 지속적으로 fine-tuning되므로 컴퓨팅을 절약하기 위해 최첨단에 도달하면 작업에 대한 fine-tuning이 중지됩니다.
전체적으로 이 모델은 265만 단계에 대해 훈련되었습니다.
'Generative AI > Language Model' 카테고리의 다른 글
| [Large Language Model] GPT-NeoX-20B (0) | 2023.07.11 |
|---|---|
| [Large Language Model] mT5-xxl (0) | 2023.07.11 |
| [Large Language Model] BLOOMZ & mT0 (0) | 2023.07.11 |
| [Large Language Model] BLOOM (0) | 2023.07.11 |
| [Large Language Model] FLAN-T5 (0) | 2023.07.11 |