Transformer 모델의 성능 향상을 위한 시도
1. 어떻게 더 많이, 더 잘 훈련시켜서 성능을 향상시킬 수 있을까?
- pre-training objective 변형, 모델 변경 등 연구 난이도가 훨씬 높고 computing resource도 많이 필요
- XLNet, RoBERTa, MT-DNN, T5
2. Transformer 구현체를 축소시키면서 성능 손실을 막고 서비스가 가능한 형태로 어떻게 바꿀까?
- Quantization, Pruning, Knowledge Distillation

T5(Text-to-Text Transfer Transformer)
Google, 2020, 110억 파라미터
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a div
arxiv.org
T5에서는 클래스 레이블 또는 입력 범위만 출력할 수 있는 BERT-style 모델과 달리 모든 NLP 작업을 입력 및 출력이 항상 텍스트 문자열인 통합 텍스트-대-텍스트 형식으로 재구성할 것을 제안합니다.
텍스트-텍스트 프레임워크를 사용하면 기계 번역, 문서 요약, 질문 응답 및 분류 작업(예: 감정 분석)을 포함한 모든 NLP 작업에서 동일한 모델, 손실(loss) 함수 및 하이퍼 파라미터(Hyper parameter)를 사용할 수 있습니다.
- Transformer Encoder/Decoder를 사용한 모델
- 번역, 요약, 질의응답 등의 모든 task들은 자연어 문장이 들어가고 자연어 문장이 나온다는 점에 착안하여 모든 NLP task를 'Text-to-Text' task로 정의
- input token에 relative position encoding을 사용
- self-attention 계산 시 offset boundary 내의 token들에 relative position encoding 값을 준 것
- self-attention 계산 시 offset boundary 내의 token들에 relative position encoding 값을 준 것

텍스트를 모델에 대한 입력으로 사용하며 일부 대상 텍스트를 생성하도록 훈련
다양한 작업 세트에서 동일한 모델, 손실 함수 및 하이퍼 파라미터를 사용
- 녹색: 번역
- 언어 수용: 빨간색
- 문장 유사성: 노란색
- 문서 요약: 파란색
T5 Example
문장: "I think therefore I am"
Offset: 2

- 0: i번째 token의 왼쪽 2번째 token
- 1: i번째 token의 왼쪽 1번째 token
- 2: i번째 token
- 3: i번째 token의 오른쪽 1번째 token
- 4: i번째 token의 오른쪽 2번째 token
C4 Dataset(Colossal Clean Crawled Corpus, 대규모 사전 훈련 데이터셋)
Wikipedia의 텍스트는 품질은 우수하지만 스타일이 균일하고 목적에 따라 상대적으로 작음
Common Crawl 웹 스크랩은 엄청나고 다양하지만 품질은 매우 낮음
→ Wikipedia보다 2배 큰 Common Crawl 버전인 C4를 개발
TensorFlow Dataset을 통해 제공됨.
- unlabeled data의 품질, 특징, 크기의 특성을 실험을 위해 Common Crawl Project의 데이터 사용
- Common Crawl은 웹에서 text source를 스크랩해서 여러 데이터 형태로 변환하는 프로젝트이며, 월 20TB의 HTML 데이터를 모으고 있음
- 전처리 후 학습에 사용된 총 데이터는 750GB
전처리
- 구두점으로 끝나는(쉼표, 마침표 등) 문장만 선택
- 불건전한 페이지의 모든 문장 제외
- javascript, lorem ipsum, { 등이 포함된 모든 문장 제외
- 3개 문장이 중복된 페이지는 하나만 남김
- langdetect를 활용하여 0.99의 확률로 영어인 페이지만 사용
전이 학습 방법론에 대한 체계적인 연구
T5 TTS(Text-to-Text) 프레임워크와 새로운 사전 훈련 데이터셋(C4)을 사용하여 NLP 전이학습에 도입된 방대한 아이디어와 방법을 조사
- 모델 아키텍처들: 엔코더 디코더 모델이 일반적으로 디코더 전용 언어 모델보다 성능이 우수
- 사전 훈련한 객체들: 빈칸 캐우기 스타일의 노이즈 제거 목표(모델이 입력에서 누락된 단어를 복구하도록 훈련된 경우)가 가장 효과적이며 가장 중요한 요소는 계산 비용이라는 것
- 레이블이 지정되지 않은 데이터셋: 도메인 내 데이터에 대한 훈련이 도움이 될 수 있지만 더 작은 데이터셋에 대한 사전 훈련은 과도한 overfitting을 초래할 수 있음
- 훈련 전략: 멀티태스킹 학습이 사전 훈련 후 정밀 조정 접근 방식으로 경쟁에 가까울 수 있지만 모델이 각 작업에 얼마나 자주 훈련되는지 주의 깊게 선택해야 함
- 모델 확장성: 학습 시간 및 앙상블 모델 수의 스케일 업을 비교하여 고정 계산 능력을 최대한 활용하는 방법을 결정하는 스케일
Downstream Tasks
통찰력 + 규모 = 최고 수준
- NLP에 대한 현재 전이 학습의 한계를 탐색하기 위해 체계적인 연구의 모든 최상의 방법을 결합하고 Google Cloud TPU 엑셀러레이터들로 접근 방식을 확장한 최종 실험 세트를 실행
- WMT(Machine Translation), GLUE, SuperGLUE(Text Classification), SQuAD(Question Answering), CNN/DailyMail(Abstractive Summarization) 벤치마크에서 최고 수준을 달성
- SuperGLUE 자연 언어 이해의 벤치마크에서 인간과 거의 비슷한 점수를 달성
Input and Output Format
- downstream(fine-tuning) task의 데이터 prefix를 붙여서 사용
확장-비공개 도서 질문 답변
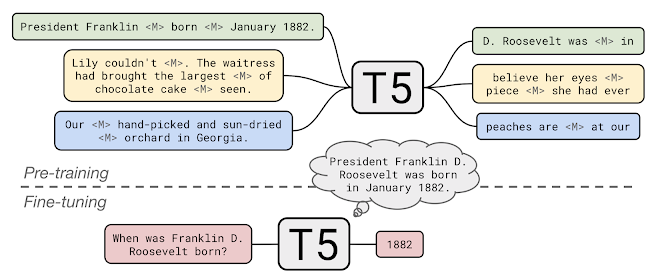
pre-training 중 T5는 C4 문서에서 누락된 텍스트 범위(<M>로 표시)를 채우는 방법을 배웁니다.
비공개 얘약 질문 답변에 T5를 적용하기 위해 추가 정보나 컨텍스트를 입력하지 않고 질문에 답변하도록 T5를 미세 조정했습니다.
이를 통해 T5는 사전 후련 과정에서 내재화 한 "지식"을 바탕으로 질문에 대답합니다.
TPU (Tensor Processing Unit)
딥러닝, 머신 러닝 워크로드를 더 빠르고 경제적으로 처리하기 위한 전용 프로세서가 필요하다는 인식 때문에 구글이 만듦
References
'Generative AI > Language Model' 카테고리의 다른 글
| [Language Model] KR-BERT (0) | 2021.04.13 |
|---|---|
| [NLP] 통계적 언어 모델(Statistical Language Model, SLM) (0) | 2021.04.12 |
| [Language Model] Multilingual BERT (0) | 2021.04.08 |
| [NLP] LDA(Latent Dirichlet Allocation) (0) | 2021.03.12 |
| [NLP] Seq2Seq Model (0) | 2021.03.12 |