GPT(Generative Pre-trained Transformer)
OpenAI에서 Transformer의 Decoder를 활용해 발표한 Pretrained 언어 모델
- GPT-1 : 2018년 발표
- GPT-2 : 2019년 2월 발표, 제한된 데모버전만 공개
- GPT-3 : 2020년 발표, 유료


Pretrained Language Model이란 레이블이 없는 많은 데이터를 비지도 학습 방법으로 학습을 해서 모델이 언어를 이해 할 수 있도록 한 후 특정 Task에 적용해서 좋은 성능을 내는 방법을 의미한다.

Unsupervised pre-training
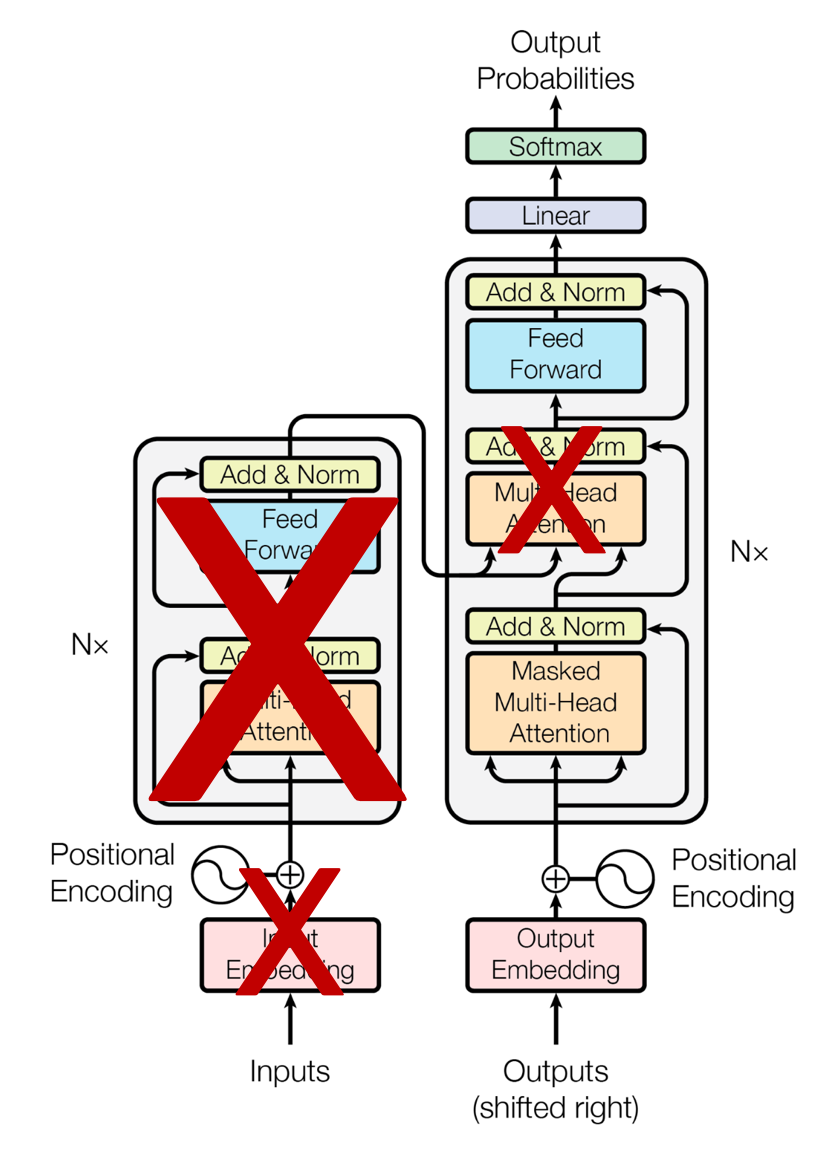
표준 Transformer의 Decoder만 사용하므로 Decoder에서 Encoder의 출력과 Attention을 하는 부분인 Encoder-Decoder Multi-Head attention 부분을 제거하였다.
그리고 12개의 transformer 층을 쌓은 후 방대한 텍스트 데이터를 이용하여 GPT-1 모델을 만들었다.
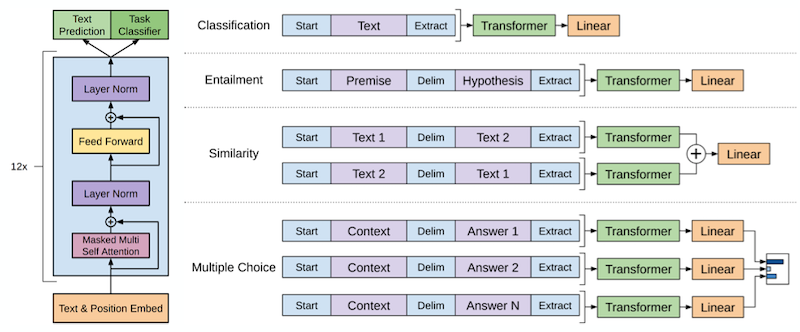
1) 큰 말뭉치에서 대용량의 언어모델 학습
2) 분류 데이터를 써서 과제에 맞춰 모델을 fine-tuning하는 방식으로 진행된다.
GPT-1은 12개 중 9개의 nlp task에서 sota(state of art)를 달성했다.


Supervised fine-tunning
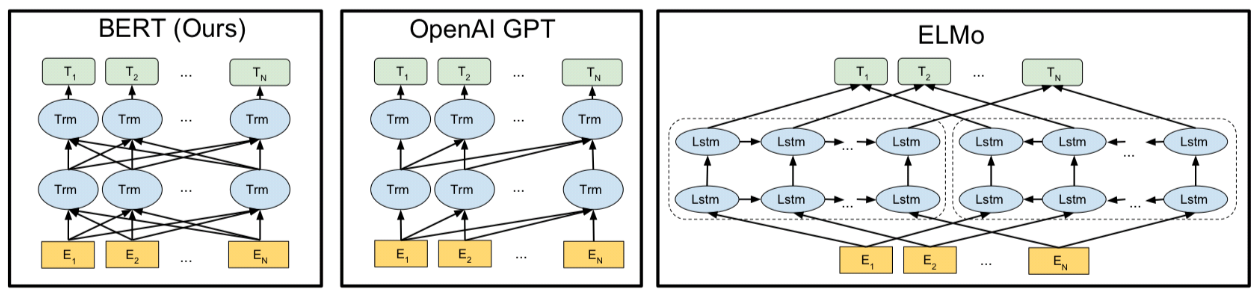
BERT vs GPT vs ELMo
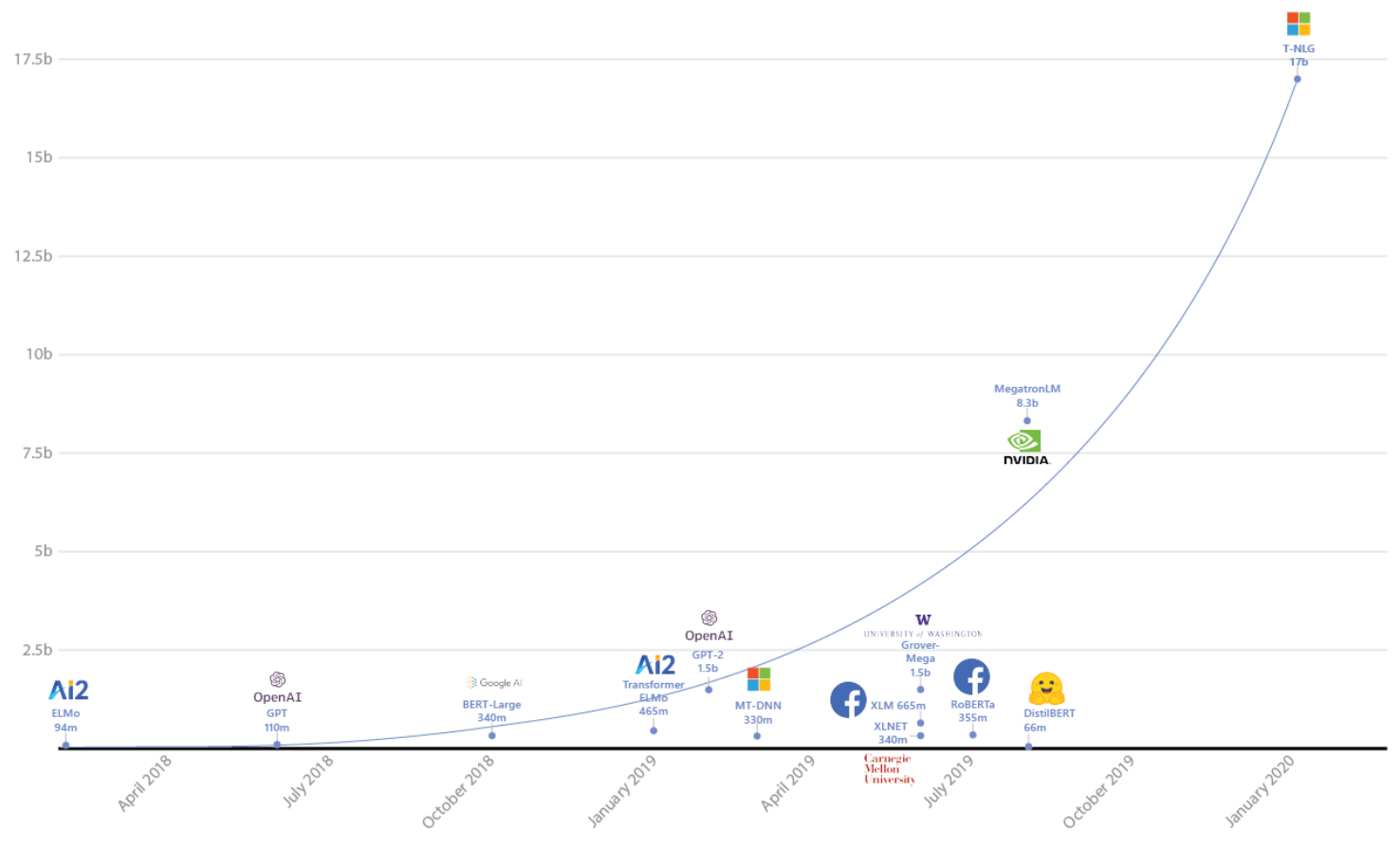
Language Models Parameter
References
- https://jalammar.github.io/illustrated-gpt2/
- https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- https://towardsdatascience.com/from-pre-trained-word-embeddings-to-pre-trained-language-models-focus-on-bert-343815627598
- https://velog.io/@tobigs-text1415/Lecture-22-BERT-and-Other-Pre-trained-Language-Models
- https://paul-hyun.github.io/gpt-01/
'Generative AI > Language Model' 카테고리의 다른 글
| [NLP] Language Model이란 (0) | 2023.03.12 |
|---|---|
| [Language Model] BERT (0) | 2022.05.09 |
| Language Model 종류 (0) | 2022.05.09 |
| [Language Model] ELMo (0) | 2022.05.09 |
| [Language Model] Transformer Model (0) | 2022.05.04 |