BERT(Bidirectional Encoder Representations for Transformers)
Pre-training of Deep Bidirectional Transformers for Language Understanding
- 2018년 10월 논문이 공개된 구글의 새로운 Language Representation Model
- 모든 자연어 처리 분야에서 좋은 성능을 내는 범용 Language Model
- 방대한 양의 Corpus(위키피디아, 웹문서, 책정보 등)를 이미 트레이닝시킨 언어 처리 모델
- arxiv.org/abs/1810.04805
github.com/google-research/bert
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
TensorFlow code and pre-trained models for BERT. Contribute to google-research/bert development by creating an account on GitHub.
github.com
Input Representation
- 3개의 입력 임베딩(Token, Segment, Position Embedding)의 합으로 구성

Token Embeddings
- 워드 임베딩 방식이 아닌 Word Piece 임베딩 방식을 사용
- 각 Char(문자) 단위로 임베딩을 하고, 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다.
- 자주 등장하는 sub-word은 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 sub-word로 쪼개짐
- Word Piece 임베딩은 모든 언어에 적용 가능하며 sub-word 단위로 단어를 분절하므로 OOV(Out-of-vocabulary) 처리에 효과적이고 정확도 상승효과도 있다
Segment Embeddings
- BERT는 두 개의 문장을 문장 구분자([SEP])와 함께 합쳐 넣는다.
- 입력 길이의 제한으로 두 문장은 합쳐서 512 subword 이하로 제한
- 입력의 길이가 길어질수록 학습시간은 제곱으로 증가하기 때문에 적절한 입력 길이를 설정 필요
- 한국어는 보통 평균 20 subword로 구성되고 99%가 60 subword를 넘지 않기 때문에 입력 길이를 두 문장이 합쳐 128로 해도 충분하다. 하지만 간혹 긴 문장이 있으므로 우선 입력 길이 128로 제한하고 학습한 후, 128보다 긴 입력들을 모아 마지막에 따로 추가 학습하는 방식을 사용한다.
Position Embedding
- BERT는 Transformer의 인코더, 디코더 중 인코더만 사용
Transformer 에서는 Sinusoid 함수를 이용한 Positional encoding을 사용하였고, BERT에서는 이를 변형하여 Position encoding을 사용 - osition encoding은 단순하게 Token 순서대로 0, 1, 2, ...와 같이 순서대로 인코딩
임베딩 취합
- 3가지의 입력 임베딩(Token, Segment, Position 임베딩)을 취합하여 하나의 임베딩 값으로 만든다.
- 그리고 이 합에 Layer Normalization과 Dropout을 적용하여 입력으로 사용한다.
언어 모델링 구조(Pre-training BERT)
- 대량 corpus로 BERT 언어 모델을 적용하고, BERT 언어 모델 출력에 추가적인 모델(RNN, CNN 등의 머신러닝 모델)을 쌓아 원하는 Task 수행
- 간단한 DNN 모델을 이용했을 때와 CNN 같은 복잡한 모델을 이용했을 때 성능 차이가 거의 없음

예를 들어, 텍스트 분류 모델을 만든다면
- 관련 대량 corpus → BERT→ 분류를 원하는 데이터 →LSTM,CNN등의머신러닝모델 → 분류
- 대량의 corpus를 encoder가 임베딩하고(언어 모델링), 이를 전이하여 fine tunning하고 task 수행(NLP Task)
Transformat의 Encoder만 사용

Pre-training BERT
Task 1: Masked Language Model (MLM)

사전 훈련을 위해 신경망 input으로 들어가는 입력 text의 15%를 랜덤으로 masking하고 masking을 예측한다.
[Mask] 토큰만 사용하면 mask token이 파인튜닝 단계에서 나타나지 않는다.
이를 해결하기 위해 다음과 같은 것을 적용한다.
- 15%의 80%는 [mask]로 설정
- my dog is hairy -> my dog is [MASK]
- 15%의 10%는 랜덤으로 단어 변경
- my dog is hairy -> my dog is apple
- 15%의 10%는 동일하게 유지
- my dog is hairy -> my dog is hairy
Task 2: Next Sentence Prediction (NSP)

QA, NLI는 두 문장간의 관계를 이해하는 것에서 시작된다.
1단계 : 위키피디아, book corpus 데이터 이용
2단계 : NSP를 위해 sentence를 뽑아서 Sentence embedding을 넣는다(이때, 50%는 진짜 sentence, 나머지는 random sentence)
3단계: masking 작업을 하고 masking 예측
Fine-tuning BERT
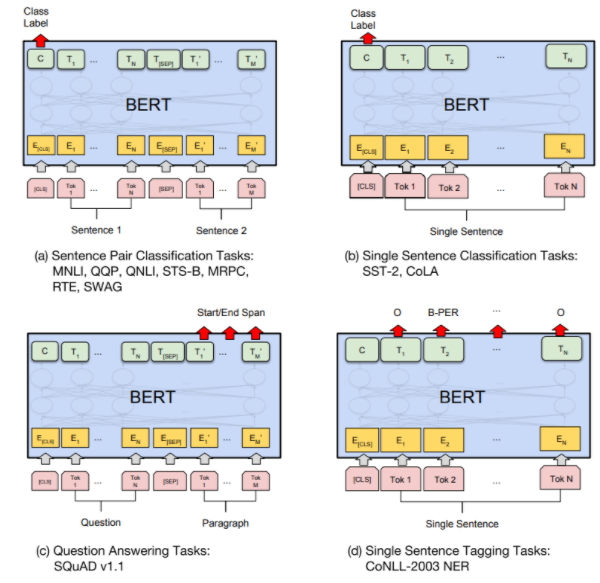
BERT 활용 예
- 감성분석
- QnA 문장 유사도(이진 분류 기반)
- QnA 문장 유사도(문장 벡터 기반): Sent2Vec 이용, 유사 문장 후보 추출
- 관계추출
- 개체명 인식
- 기계독해
BERT 성능에 영향을 미치는 요인
- Corpus 사이즈
- Corpus 도메인
- Corpus tokenizing(어절, BPE, 형태소)
- Vocab 사이즈
※ 주요 성능 차이는 전처리의 차이에서도 발생한다.
BERT 한계
BERT는 일반 NLP모델에서 잘 작동하지만, Bio, Science, Finace 등 특정 분야의 언어모델에 사용하려면 잘 적용되지 않음
특정 분야에 대해 BERT를 적용하려면 특정 분야의 특성을 수집할 수 있는 언어데이터들을 수집하고, 언어모델 학습을 추가적으로 진행 필요
References
'Generative AI > Language Model' 카테고리의 다른 글
| [Foundation Model] GPT-4 / GPT-3 (0) | 2023.04.12 |
|---|---|
| [NLP] Language Model이란 (0) | 2023.03.12 |
| [Language Model] GPT (0) | 2022.05.09 |
| Language Model 종류 (0) | 2022.05.09 |
| [Language Model] ELMo (0) | 2022.05.09 |