반응형
GoogleNet
- Inception 모듈 사용
- 22개의 layers, 5M parameters (AlexNET의 1/12 수준)


GoogleNet 컨셉
- Layer의 깊이를 늘려 성능을 높이고자 했으나 다음과 같은 문제 발생
- free paremeter 수 증가
- 데이터 학습양이 작으면 overfitting 문제
- 연산량이 늘어남(필터의 개수가 증가하면 연산량은 제곱 증가)
- Vanishing Gradient 문제
- 학습은 잘되었으나 테스트할 때 성능이 나오지 않을 수 있다
- 또한, 모델이 너무 커져 학습과 테스트에 많은 시간을 소비하게 된다
NIN (Network In Network)
- 일반적인 CNN은 Feature Extraction(convolution + pooling) + classifier(fully connected NN)로 구성
- Local receptive field에서 feature 추출 능력은 우수하지만 비선형 성질의 feature 추출은 한계
- NN의 경우 비 선형적인 특징을 잘 추출하는 특징이 있어 이것을 활용한 구조화
MLP Conv

MLP 여러개로 쌓은 구조

- classifier에 fully connected NN가 없음
- fully connected NN 대신에 Global Average Pooling 사용
- 효과적인 feature-vector를 추출하였기 때문에 pooling만으로 충분하다고 주장
- 연산량 대폭 줄임
1x1 Convolution

NIN은 일반적인 convolution 연산 후 MLP을 대신하여 1x1 convolution 연산
- MLP와 같은 효과 얻을 수 있음(비선형 특징점 추출)
- 차원 축소(30x30의 feature map 10개를 30x30 feature map 5개로 줄일 수 있음)
Inception Module
 |
 |
- 1x1 convolution, 3x3 convolution, 5x5 convolution, 3x3 max pooling을 나란히 놓아 다양한 scale feature를 추출
- local receptive field에서 더 많은 feature를 추출하기 위해 여러 개의 convolution 적용
- feature 추출 등의 과정은 최대한 sparse함을 유지
- 행렬 연산 제차는 이들을 합쳐 최대한 dense하게 만듦
- 1x1 convolution: 차원 축소
- NIN의 형태와 비슷: 비선형 feature와 차원 축소에 대한 장점 모두 활용
- 핵심 설계 목표는 주어진 하드웨어 자원을 최대한 효율적으로 이용하면서 학습 능력은 극대화할 수 있는 깊고 넓은 망을 갖는 구조 설계
- 인셉션 모듈에 있는 다양한 크기의 convolution kernel을 통해 다양한 scale의 feature을 효과적으로 추출
- 1x1 convolution을 통해 연산량을 크게 경감시킴
- layer의 넓이와 깊이가 증가됨
- 인셉션 모듈을 통해 NIN 구조를 갖는 deep한 CNN을 설계할 수 있게 됨
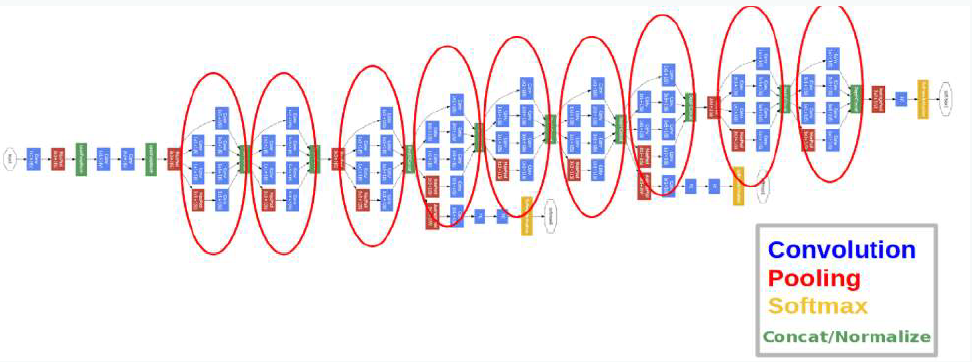
Auxiliary Classifier

- 엄청나게 깊은 네트워크에서 Vanishing Gradient 문제 발생
- Auxiliary Claasifier를 덧붙여 loss를 맨 끝 뿐만 아니라 중간 중간에서 구하기 때문에 기울기가 적절하게 역전파
- 지나친 영향을 막기 위해 auxiliary classifier의 loss는 0.3을 곱함
- 실제 테스트 과정에서는 auxiliary classifier를 제거하고 제일 마지막의 softmax만 사용
728x90
반응형
'Machine Learning > CNN' 카테고리의 다른 글
| [Machine Learning] Transfer Learning with CNNs (0) | 2021.03.05 |
|---|---|
| [Machine Learning] ResNet(Residual Network) (0) | 2021.03.05 |
| [Machine Learning] VGGNet (0) | 2021.03.05 |
| [Machine Learning] AlexNet (0) | 2021.03.05 |
| [Machine Learning] CNN(Convolutional Neural Network) (0) | 2021.03.02 |