728x90
반응형
k-최근접 이웃(K-Nearest Neighbor, KNN)
가장 간단한 머신러닝 알고리즘
장점
- 구현이 쉽다
- 알고리즘을 이해하기 쉽다
- 수학적으로 거리를 계산하는 방법만 알면 이해하기가 쉽다
- 숫자로 구분된 속성에 우수한 성능을 보인다.
- 별도의 모델 학습이 필요 없다.
- Hyper-parameter가 적다
단점
- 예측 속도가 느리다
- 하나의 데이터를 예측할 때마다 전체 데이터와의 거리를 계산해야 한다
- 메모리를 많이 사용한다
- 노이즈 데이터(수집된 데이터가 참값만 가지고 있지 않을 경우)에 예민하다
- 예측값이 편향될 수 있다
- 학습된 모델이 아닌 가까운 이웃을 통해 예측하기 때문에 예측값이 틀릴 가능성이 상대적으로 높아진다
가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측하는 방법
- 숫자 k와 거리 측정 기준으로 선택
- 분류하려는 샘플에서 k개의 최근접 이웃을 찾음
- 다수결 투표를 통해 클래스 레이블을 할당
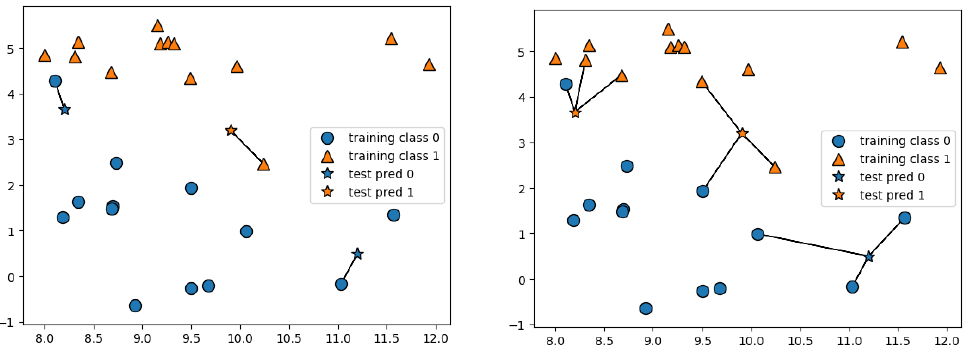

최근접 이웃의 수가 하나 일때는 훈련 데이터의 대한 예측이 완벽하지만
테스트 데이터의 정확도는 낮게 나온다.
: k(탐색할 이웃의 개수)는 보통 1로 설정하지 않음
정확도가 가장 좋을 때는 중간 정도의 최근접 이웃이 6개 정도
: k는 보통 홀수로 설정하는데, k가 짝수일 경우 과반수 이상의 이웃이 나오지 않을 수 있기 때문임.
KNN 알고리즘의 장점은 이해하기 쉬우면서 많은 조정없이 괜찮은 성능을 발휘
References
728x90
반응형
'Machine Learning > Supervised Learning' 카테고리의 다른 글
| [Supervised Learning][Classification] SVM(Support Vector Machine) (0) | 2021.03.24 |
|---|---|
| [Supervised Learning] Ensemble (0) | 2021.03.24 |
| [Supervised Learning] Decision Tree (0) | 2021.03.24 |
| [Supervised Learning][Regression] Linear Regression (0) | 2021.03.24 |
| [Supervised Learning][Classification] Logistic Regression (0) | 2021.03.01 |