python-pptx
a Python library for creating and updating PowerPoint (.pptx) files
파워포인트(.pptx) 파일의 슬라이드 내 데이터를 추출하여 분석하고자 하는 경우 python-pptx를 활용할 수 있다.
python-pptx — python-pptx 0.6.21 documentation
python-pptx.readthedocs.io
GitHub - scanny/python-pptx: Create Open XML PowerPoint documents in Python
Create Open XML PowerPoint documents in Python. Contribute to scanny/python-pptx development by creating an account on GitHub.
github.com
python-pptx 설치
pip install python-pptx
python-pptx 사용한 문서 데이터 추출
python-pptx를 사용하여 파워포인트 파일을 읽을 경우 슬라이드 내의 정보를 객체 형태로 반환해준다.
슬라이드 내의 텍스트, 테이블, 임베드 개체 등 원하는 항목에서 텍스트를 추출하거나, 데이터를 엑셀 파일로 저장 또는 이미지 파일 저장 등이 가능하다.
샘플 파워포인트 파일
문서 데이터 추출을 위한 샘플 파일(sample.pptx)을 다음과 같이 구성하였다.
- 텍스트 상자, 표, 이미지, 엑셀 개체 추가
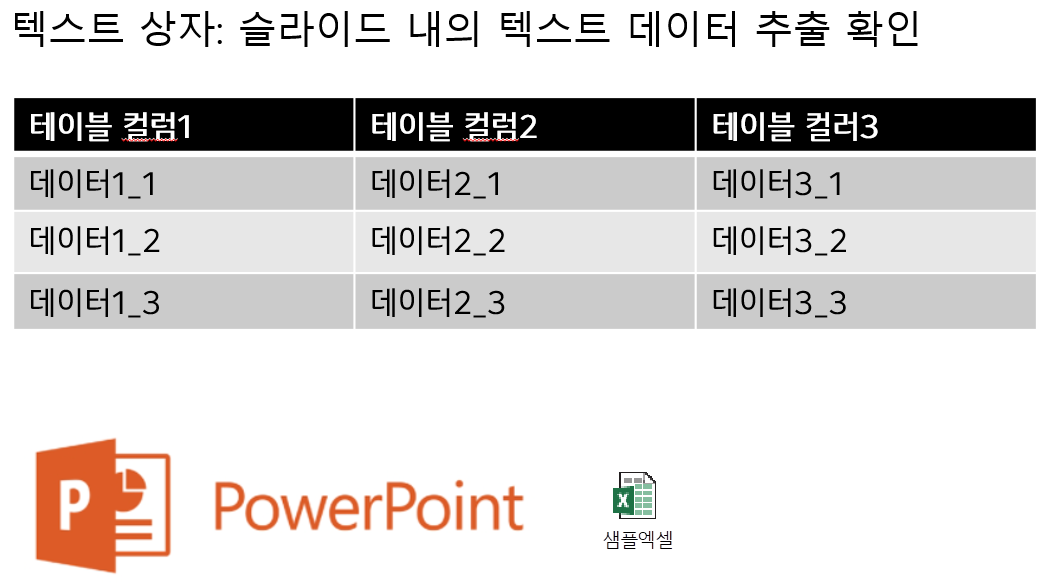
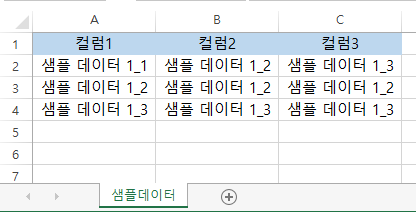
Embed 엑셀 파일을 다음과 같이 작성해서 파워포인트에 개체로 추가한다.
[TEXT_BOX] 텍스트 정보 추출
슬라이드 내에 포함된 텍스트 상자의 텍스트를 추출할 수 있다.
슬라이드 정보의 shape의 shape_type을 확인하면 개체를 구분할 수 있다.
https://python-pptx.readthedocs.io/en/latest/api/enum/MsoShapeType.html?highlight=MSO_SHAPE_TYPE
MSO_SHAPE_TYPE — python-pptx 0.6.21 documentation
MSO_SHAPE_TYPE Specifies the type of a shape Alias: MSO Example: from pptx.enum.shapes import MSO_SHAPE_TYPE assert shape.type == MSO_SHAPE_TYPE.PICTURE AUTO_SHAPE AutoShape CALLOUT Callout shape CANVAS Drawing canvas CHART Chart, e.g. pie chart, bar chart
python-pptx.readthedocs.io
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
# 파일 읽어오기
parsed = Presentation("sample.pptx")
# 슬라이드 별로 순회하면서 데이터 추출
for slide in parsed.slides:
# 슬라이드 내 개체들이 shapes
for shape in slide.shapes:
print(shape.shape_type)
# Text Box의 텍스트 출력
if shape.shape_type == MSO_SHAPE_TYPE.TEXT_BOX:
print(shape.text_frame.text)결과
TEXT_BOX (17)
텍스트 상자: 슬라이드 내의 텍스트 데이터 추출 확인
[TABLE] 테이블 정보 추출
테이블의 정보에서 column, row 별 텍스트 정보를 추출하여 pandas Dataframe으로 구성하여 정보를 처리할 수 있다.
import pandas as pd
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
# 파일 읽어오기
parsed = Presentation("sample.pptx")
# 슬라이드 별로 순회하면서 데이터 추출
for slide in parsed.slides:
table_data = [] # TABLE 저장
# 슬라이드 내 개체들이 shapes
for shape in slide.shapes:
print(shape.shape_type)
# TABLE 정보 추출
if shape.shape_type == MSO_SHAPE_TYPE.TABLE:
row_count = len(shape.table.rows)
col_count = len(shape.table.columns)
for _r in range(0, row_count):
row = []
for _c in range(0, col_count):
cell = shape.table.cell(_r, _c)
# row 별 데이터를 array로 저장
row.append(cell.text)
# row 데이터를 전체 데이터 저장 array에 저장
table_data.append(row)
print(table_data)
# 필요에 따라서는 pandas의 dataframe 등을 이용해서 데이터 저장
df_temp = pd.DataFrame(columns=table_data[0], data=table_data[1:])
print(df_temp)결과
TABLE (19)
[['테이블 컬럼1', '테이블 컬럼2', '테이블 컬러3'], ['데이터1_1', '데이터2_1', '데이터3_1'], ['데이터1_2', '데이터2_2', '데이터3_2'], ['데이터1_3', '데이터2_3', '데이터3_3']]
테이블 컬럼1 테이블 컬럼2 테이블 컬러3
0 데이터1_1 데이터2_1 데이터3_1
1 데이터1_2 데이터2_2 데이터3_2
2 데이터1_3 데이터2_3 데이터3_3
[PICTURE] 이미지 파일 정보 추출
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
# 파일 읽어오기
parsed = Presentation("sample.pptx")
# 슬라이드 별로 순회하면서 데이터 추출
for slide in parsed.slides:
# 슬라이드 내 개체들이 shapes
for shape in slide.shapes:
print(shape.shape_type)
# 이미지 정보를 별도 파일로 저장
if shape.shape_type == MSO_SHAPE_TYPE.PICTURE:
image_blob = shape.image.blob
ext = shape.image.ext
with open(f"image.{ext}", "wb") as file:
file.write(image_blob)결과
image.png 파일이 저장됨

[EMBEDDED_OLE_OBJECT] 엑셀 개체 정보 추출
oleformat의 blob 정보에서 개체 정보를 바로 추출하거나 별도 파일로 저장할 수 있다.
https://python-pptx.readthedocs.io/en/latest/_modules/pptx/shapes/graphfrm.html?highlight=blob#
pptx.shapes.graphfrm — python-pptx 0.6.21 documentation
python-pptx.readthedocs.io
shape.ole_format.blob
class _OleFormat(ParentedElementProxy):
"""Provides attributes on an embedded OLE object."""
@property
def blob(self):
"""Optional bytes of OLE object, suitable for loading or saving as a file.
This value is None if the embedded object does not represent a "file".
"""
return self.part.related_part(self._graphicData.blob_rId).blobembeded object의 정보는 blob (bytes)로 추출된다.
이 정보를 BytesIO()를 이용해 읽고 pandas 또는 openpyxl을 이용해서 원하는 형태의 데이터로 추출한다.
import pandas as pd
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
from io import BytesIO
from openpyxl import load_workbook
# 파일 읽어오기
parsed = Presentation("sample.pptx")
# 슬라이드 별로 순회하면서 데이터 추출
for slide in parsed.slides:
# 슬라이드 내 개체들이 shapes
for shape in slide.shapes:
print(shape.shape_type)
#Embeded Object 정보 추출
if shape.shape_type == MSO_SHAPE_TYPE.EMBEDDED_OLE_OBJECT:
# 엑셀 파일인지 확인
if shape.ole_format.prog_id == "Excel.Sheet.12":
embed_blob = shape.ole_format.blob
print(type(embed_blob))
toread = BytesIO()
toread.write(embed_blob)
toread.seek(0)
# dataframe으로 바로 읽는 경우,
# 엑셀 파일 내 sheet가 여러 개인 경우에는 첫번째 sheet 정보가 dataframe으로 추출된다
df = pd.read_excel(toread)
print(df)
# 별도 엑셀 파일로 저장하는 경우
workbook = load_workbook(toread)
workbook.save("test.xlsx")
for sheet in workbook.worksheets:
print(sheet)
df_temp = pd.DataFrame(sheet.values)결과
EMBEDDED_OLE_OBJECT (7)
<class 'bytes'>
컬럼1 컬럼2 컬럼3
0 샘플 데이터 1_1 샘플 데이터 1_2 샘플 데이터 1_3
1 샘플 데이터 1_2 샘플 데이터 1_2 샘플 데이터 1_2
2 샘플 데이터 1_3 샘플 데이터 1_3 샘플 데이터 1_3
<Worksheet "샘플데이터">
'Python > 문서 데이터 분석' 카테고리의 다른 글
| [Python] [tabula-py] PDF 파일 정보 추출 (0) | 2022.01.10 |
|---|---|
| [Python] [PyMuPDF] PDF 파일 정보 추출 (0) | 2022.01.10 |
| [Python] [PyPDF2] PDF 파일 정보 추출 (0) | 2022.01.10 |
| [Python] Python을 이용한 PDF 파일 정보 추출 (0) | 2022.01.09 |
| [Python] Python을 이용한 Powerpoint 파일 정보 추출 비교 (0) | 2022.01.09 |