반응형
PyMuPDF 설치
pip install PyMuPDF
PyMuPDF를 이용한 파일 정보 추출
import fitz
pdf_doc = fitz.open("sample.pdf")
# number of pages
print(f"전체 Page 수: {pdf_doc.page_count}")
# Get the first page
page = pdf_doc.load_page(0)
# page 내의 텍스트 추출
print(page.get_text())결과
전체 Page 수:1
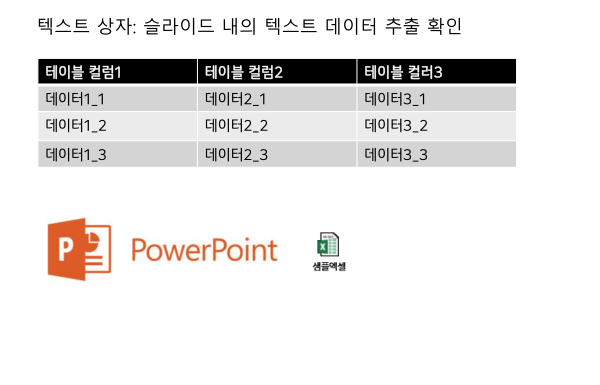
텍스트 상자: 슬라이드 내의 텍스트 데이터 추출 확인
테이블 컬럼1
테이블 컬럼2
테이블 컬러3
데이터1_1
데이터2_1
데이터3_1
데이터1_2
데이터2_2
데이터3_2
데이터1_3
데이터2_3
데이터3_3※ 한글 텍스트가 정상 추출됨을 알 수 있다.
PyMuPDF를 이용한 PDF 파일 이미지로 저장
import fitz
pdf_doc = fitz.open("sample.pdf")
# Get the first page
page = pdf_doc.load_page(0)
# pdf 파일 이미지 저장
pix = page.get_pixmap()
output = "output.png"
pix.save(output)결과(output.png)
728x90
반응형
'Python > 문서 데이터 분석' 카테고리의 다른 글
| [Python] [tika-python] PDF, Powerpoint 정보 추출 (0) | 2022.01.10 |
|---|---|
| [Python] [tabula-py] PDF 파일 정보 추출 (0) | 2022.01.10 |
| [Python] [PyPDF2] PDF 파일 정보 추출 (0) | 2022.01.10 |
| [Python] Python을 이용한 PDF 파일 정보 추출 (0) | 2022.01.09 |
| [Python] Python을 이용한 Powerpoint 파일 정보 추출 비교 (0) | 2022.01.09 |