728x90
반응형
차원축소 (Dimensionality Reduction)
- 가지고 있는 방대한 양의 데이터에서 필요한 특성만 추출하는 방법
- 너무 많은 정보를 잃지 않으면서 데이터를 간소화
- 새로운 데이터를 잘 예측해주는 '설명력'있는 모델을 구현하기 위해 데이터의 특성을 잘 설명해주는 중요한 차원들만 골라주는 작업
- 차원축소를 통해 중요한 특징들만 골라 어떻게 분포하고 있는지 대략적으로 확인
- 모델이 복잡해질수록 필요한 연산량이 많이지기 때문에 시간이 오래 걸리나, 차원축소를 통해 필요한 특징들만 골라내서 연산도 가볍고 데이터 저장공간 확보도 용이
PCA (주성분 분석, Principal Component Analysis)
- 차원축소의 가장 대표적인 알고리즘
- 분산이 최대인 축을 찾고 이 축과 직교이면서 분산이 최대인 두번째 축을 찾아 투영시키는 방법
- 원데이터의 분산을 최대한 보존하는 목적을 가짐
- 공분산 행렬의 고유값과 고유 벡터를 구하여 산출
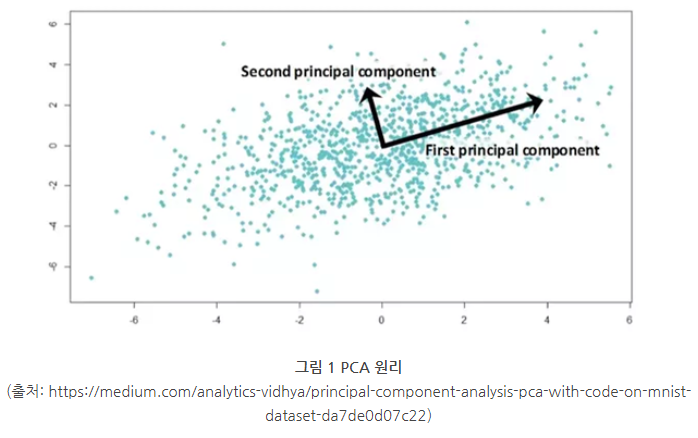
단점
- 생성된 두 축의 해석이 어렵고 선형 방식으로 정사영하기 때문에 차원이 줄어들면서 군집된 데이터들이 뭉개질 수 있음

3개의 클러스터를 y축에 투영시켰을 때
빨간색과 파란색 클러스터가 뭉개짐
t-SNE (t-Stochastic Neighbor Embedding)
- 고차원의 벡터의 유사성이 저차원에서도 유사하도록 보존하는 방법
- t분포를 이용하여 하나의 기준점을 정하고 모든 다른 데이터와 거리를 구한 후 그 값에 해당하는 t분포 값을 선택하여 값이 유사한 데이터끼리 묶어주는 방법

단점
- 데이터의 개수가 n개라면 연산량은 n의 제곱만큼 늘어나기 때문에 시간이 오래 걸릴 수 있다
- 매번 실행 시마다 다른 시각화 결과가 나온다
- 2, 3차원으로만 줄일 수 있다(초고차원의 데이터를 10차원 정도로 줄이는 것은 불가능)
UMAP(Uniform Manifold Approximation and Projection)
- Topological data 분석으로 아이디어와 manifold learning 기술을 기반으로 한 차원 축소 알고리즘
- 수학적으로 t-SNE보다 더 견고히 설계
- 비선형 방식의 매니폴드 학습 기술을 기반으로 한 차원축소 방법
lmcinnes/umap
Uniform Manifold Approximation and Projection. Contribute to lmcinnes/umap development by creating an account on GitHub.
github.com
UMAP 설치
pip install umap-learn
UMAP Parameters
참고: https://umap-learn.readthedocs.io/en/latest/
n_neighbors
- This determines the number of neighboring points used in local approximations of manifold structure. Larger values will result in more global structure being preserved at the loss of detailed local structure. In general this parameter should often be in the range 5 to 50, with a choice of 10 to 15 being a sensible default.
min_dist
- This controls how tightly the embedding is allowed compress points together. Larger values ensure embedded points are more evenly distributed, while smaller values allow the algorithm to optimise more accurately with regard to local structure. Sensible values are in the range 0.001 to 0.5, with 0.1 being a reasonable default.
metric
- This determines the choice of metric used to measure distance in the input space. A wide variety of metrics are already coded, and a user defined function can be passed as long as it has been JITd by numba
- Minkowski style metrics
- euclidean
- manhattan
- chebyshev
- minkowski
- canberra
- braycurtis
- haversine
- mahalanobis
- wminkowski
- seuclidean
- cosine
- correlation
- hamming
- jaccard
- dice
- russellrao
- kulsinski
- rogerstanimoto
- sokalmichener
- sokalsneath
- yule
from umap import UMAP
# n_neighbors, n_components
# 차원이 너무 낮으면 정보가 손실되고 차원이 너무 높으면 클러스터링 결과가 나빠짐
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric="cosine", random_state=42)
References
728x90
반응형
'Machine Learning > Machine Learning' 카테고리의 다른 글
| Data Mining (데이터 마이닝) (1) | 2022.10.05 |
|---|---|
| [Machine Learning][Model Performance Measure] Precision, Recall, Accuracy, F1 score, FPR, ROC curve, AUC (0) | 2022.09.27 |
| [Machine Learning] Transfer Learning (0) | 2021.03.12 |
| [Machine Learning] ML Hyperparameter (0) | 2021.03.05 |
| [Machine Learning] Regularization (0) | 2021.03.04 |