반응형
Word2Vec
신경망 모델을 사용하여 큰 텍스트 corpus에서 단어 연관성을 학습
단어의 의미가 벡터로 표현됨으로써 벡터 연산이 가능
단어가 가지는 의미 자체를 다차원 공간에 벡터화 하는 것
- 카운트 기반 방법으로 만든 단어 벡터보다 단어 간의 유사도를 잘 측정
- 단어들의 복잡한 특징까지도 잘 잡아낸다
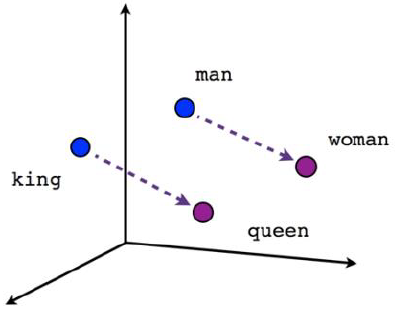
장점
- 단어간의 유사도 측정이 용이
- 단어간의 관계 파악에 용이
- 벡터 연산을 통한 추론이 가능
단점
- 단어의 subword 정보 무시(ex. 서울/서울시/고양시)
- OOV(Out of vocabulary)에서 적용 불가능

CBOW(Continuous Bag of Words)
어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법
입력 값으로 여러 개의 단어를 사용하고, 학습을 위해 하나의 단어와 비교
CBOW 학습 과정
- 입력층 벡터: 각 주변 단어들을 one-hot 벡터로 만들어 입력값으로 사용
- N-차원 은닉층: weight matrix을 각 one-hot 벡터에 곱해서 n-차원 벡터를 만듦
- 출력층 벡터: 만들어진 n-차원 벡터를 모두 더한 후 개수로 나눠 평균 n-차원 벡터를 만듦
- n-차원 벡터에 다시 weight matrix를 곱해서 one-hot 벡터와 같은 차원의 벡터로 만듦
- 만들어진 벡터를 실제 예측하려고 하는 단어의 one-hot 벡터와 비교해서 학습
Skip-Gram
어떤 단어를 가지고 특정 문맥 안의 주변 단어를 예측하는 방법
입력값이 하나의 단어를 사용하고, 학습을 위해 주변 여러 단어와 비교
CBOW보다 성능이 좋아 일반적으로 사용
Skip-Gram 학습 과정
- 입력측 벡터: 하나의 단어를 one-hot 벡터로 만들어서 입력값으로 사용
- N-차원 은닉층: 가중치 행렬을 one-hot 벡터에 곱해서 n-차원 벡터를 만듦
- 출력층 벡터: n-차원 벡터에 다시 가중치 행렬을 곱해서 one-hot 벡터와 같은 차원의 벡터로 만듦
- 만들어진 벡터를 실제 예측하려는 주변 단어들 각각의 one-hot 벡터와 비교해서 학습

Hyperparameters
size
- word vector 특징값 수.
- 각 단어에 대해 임베딩된 벡터의 차원을 정함
min_count
- 단어에 대한 최소 빈도 수.
- 모델에 의미 있는 단어를 가지고 학습하기 위해 적은 빈도 수의 단어들은 학습하지 않음
workers
- 프로세스 개수.
- 모델 학습 시 학습을 위한 프로세스 개수를 지정
window
- context 윈도 크기.
- word2vec를 수행하기 위한 컨텍스트 윈도 크기를 지정
sample
- downsampling 비율.
- word2vec 학습을 수행할 때 빠른 학습을 위해 정답 단어 라벨에 대한 다운샘플링 비율을 지정
- 보통 0.001이 좋은 성능을 냄
Word2Vec 사용
- Gensim을 이용해서 사용 가능
- [NLP/NLP 기초] - Gensim
References
728x90
반응형
'NLP > Embedding' 카테고리의 다른 글
| 부분구문분석(청크나누기, Chunking) (0) | 2023.07.18 |
|---|---|
| [NLP] Doc2Vec (0) | 2021.04.08 |
| [NLP] Word Embedding (0) | 2021.03.11 |