Doc2Vec 개념 및 방법
개념
- Word2Vec에 이어 구글 연구팀이 개발한 문서 임베딩 기법(Le&Mikolov, 2014)
- 타겟 단어와 이전 단어 k 개가 주어졌을 때, 이전 단어들 + 해당 문서의 아이디로 타겟 단어를 예측하는 과정에서 문맥이 비슷한 문서 벡터와 단어 벡터가 유사하게(코사인 유사도) 임베딩
- 문장 전체를 처음부터 끝까지 한 단어씩 슬라이딩해 가면서 다음 단어가 무엇일지 예측
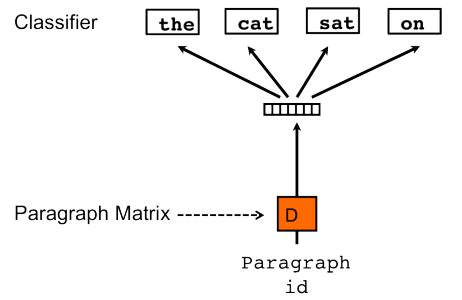
PV-DM(The Distributed Memory Model of Paragraph Vectors)
단어 등장 순서를 고려하는 방식으로 학습하기 때문에 순서 정보를 무시하는 백오브워즈 기법 대비 강점이 있다고 주장
paragraph_1 이라는 문서에서 the cat sat on the mat 라는 문장이 있을 때, 다음과 같이 학습 데이터가 구성
- 윈도우 사이즈 : k = 3
- [pragraph_1, the, cat, sat] - on
- [pragraph_1, cat, sat, on] - the
- [pragraph_1, sat, on, the] - mat
paragraph 에서 단어를 예측하며 로그 확률 평균을 최대화하는 과정에서 학습
paragraph_id 가 학습의 입력 데이터로 들어가기 때문에, 문맥이나 단어가 paragraph 벡터에 녹아든다고 볼 수 있음
각 문서 paragraph 는 별도의 문서의 수 x D 차원 의 행렬에 담기는데,
학습이 완료된 후 이 행렬을 이용하여 paragraph 의 임베딩된 벡터를 사용

PV-DBOW(The Distributed Bag of Words version of Paragraph Vector)
Word2Vec의 Skip-Gram 모델을 기반
하나의 paragraph_id 로 해당 문서 내 단어들을 예측하는 과정에서 학습
문서 ID에 해당하는 문서 임베딩엔 문서에 등장하는 모든 단어의 의미 정보가 반영
Doc2Vec 사용
- Gensim을 이용해서 사용 가능
- [NLP/NLP 기초] - Gensim
Doc2Vec Example
#Import all the dependencies
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
data = ["I love machine learning. Its awesome.",
"I love coding in python",
"I love building chatbots",
"they chat amagingly well"]
tagged_data = [TaggedDocument(words=word_tokenize(_d.lower()), tags=[str(i)]) for i, _d in enumerate(data)]
max_epochs = 100
vec_size = 20
alpha = 0.025
model = Doc2Vec(size=vec_size,
alpha=alpha,
min_alpha=0.00025,
min_count=1,
dm =1)
model.build_vocab(tagged_data)
for epoch in range(max_epochs):
print('iteration {0}'.format(epoch))
model.train(tagged_data,
total_examples=model.corpus_count,
epochs=model.iter)
# decrease the learning rate
model.alpha -= 0.0002
# fix the learning rate, no decay
model.min_alpha = model.alpha
model.save("d2v.model")
print("Model Saved")from gensim.models.doc2vec import Doc2Vec
model= Doc2Vec.load("d2v.model")
#to find the vector of a document which is not in training data
test_data = word_tokenize("I love chatbots".lower())
v1 = model.infer_vector(test_data)
print("V1_infer", v1)
# to find most similar doc using tags
similar_doc = model.docvecs.most_similar('1')
print(similar_doc)
# to find vector of doc in training data using tags or in other words, printing the vector of document at index 1 in training data
print(model.docvecs['1'])
Doc2Vec API
radimrehurek.com/gensim/models/doc2vec.html
Gensim: topic modelling for humans
Efficient topic modelling in Python
radimrehurek.com
Doc2Vec GitHub
https://github.com/RaRe-Technologies/gensim/tree/develop/gensim/models
RaRe-Technologies/gensim
Topic Modelling for Humans. Contribute to RaRe-Technologies/gensim development by creating an account on GitHub.
github.com
Doc2Vec 사용 예제
https://github.com/RaRe-Technologies/gensim/blob/develop/docs/notebooks/doc2vec-IMDB.ipynb
RaRe-Technologies/gensim
Topic Modelling for Humans. Contribute to RaRe-Technologies/gensim development by creating an account on GitHub.
github.com
References
'NLP > Embedding' 카테고리의 다른 글
| 부분구문분석(청크나누기, Chunking) (0) | 2023.07.18 |
|---|---|
| [NLP] Word2Vec (0) | 2021.03.12 |
| [NLP] Word Embedding (0) | 2021.03.11 |