모델 경량화
딥러닝 모델의 경우 모바일이나 임베디드 환경에서, 메모리, 성능, 저장공간 등의 제한이 있기 때문에 추론하기가 어렵습니다.
딥러닝 모델을 경량화와 관련된 연구들("모델을 가볍게 만드는 연구")이 많이 진행되고 있습니다.
모델 경량화 연구는 크게 두 가지로 나뉩니다.
- 모델을 구성하는 알고리즘 자체를 효율적인 구조로 설계하는 연구
- 기존 모델의 파라미터들을 줄이거나 압축하는 연구
모델을 구성하는 알고리즘 자체를 효율적인 구조로 설계하는 연구
- 모델 구조 변경: 모델 구조를 변경함으로써 경량화하는 방법 (ResNet, DenseNet, SqueezeNet, etc.)
- 효율적인 합성곱 필터 기술: 채널을 분리시켜, 연산량과 변수의 개수를 줄임으로써 경량화하는 방법 (MobileNet, ShuffleNet, etc.)
- 경량 모델 자동 탐색 기술: 자동 탐색 기법을 사용해, 경량화할 수 있는 모델 구조와 합성곱 필터를 설계하는 방법 (NetAdapt, MNAsNet, etc.)
기존 모델의 파라미터들을 줄이거나 압축하는 연구
- 가중치 가지치기(Weight Prunning): 결과에 영향을 미치는 파라미터들을 제외한 나머지 파라미터들을 0으로 설정하는 방법
- 양자화(Quantization): 부동소수점으로 표현되는 파라미터들을 특정 비트 수로 줄이는 방법
- 이진화(Binarization): 파라미터들을 이진화(예, -1과 1로만 표현)함으로써, 표현력은 줄어들지만, 정확도의 손실은 최소로하는 경량화 방법
Quantization (양자화)
neural network 모델의 내부는 대부분 weight와 activation output으로 구성되어 있습니다.
weight와 activation output은 모델의 정확도를 높이기 위해, 32bit floating point(FP32)로 표현되고 있습니다.


리소스가 제한된 환경에서 모든 weight와 activiation output을 32bit floating point로 표현한 모델은 추론에 사용하기 어렵습니다.
양자화는 weight와 activiation output 표현에 사용되는 비트 수를 줄임으로써, 모델의 크기를 줄이는 것을 의미합니다.
기존 모델보다 성능은 떨어질 수 있지만, 모델의 크기가 줄어들기 때문에, 제한된 리소스 환경에서도 사용할 수 있게 됩니다.
양자화는 training time을 줄이는 것이 아니라, Inference time을 줄이는 것이 주 목적입니다.
양자화를 사용하는 경우
- 모바일 기기나 에지 디바이스와 같이 계산 자원이 제한적인 환경에서 사용
- 실시간 추론이 필요한 시스템에서 빠른 모델 실행 속도를 요구할 때 사용
- 대규모 모델을 배포하거나 저장할 때 메모리 사용량을 줄이고자 하는 경우
양자화 예시

각 계층의 소수값(Float32)들 중, 최소/최대 값을 구합니다.
해당 소수값(Float32)들을, 선형적으로 가장 가까운 정수값(Int8)에 매핑합니다.
예를 들어, 기존 계층의 소수값 범위가 -3.0 부터 6.0 까지라면, -3.0 은 -127 로, 6.0 은 +127 로 매핑됩니다.
이 방식을 사용한다면, 32bit 로 표현되는 weight 를 적은 bit 로 표현할 수 있으므로, 메모리 감소 효과 를 볼 수 있습니다.
언어 모델에서 양자화란,
언어 모델의 매개변수를 실수형에서 정수형으로 바꾸어 비트 수를 줄이는 과정을 말합니다.
예를 들어, 32비트 부동 소수점 형태의 매개변수를 8비트 정수로 변환하는 것과 같이 비트 수를 감소시켜서 모델 사이즈를 줄이는 방식입니다.

양자화된 언어 모델은 크기가 줄어들며, 계산의 효율성이 향상됩니다.
비트 수를 N배로 줄이면 곱셈의 복잡도는 NxN로 감소하게 되며, 이에 따라 float32를 사용하는 대신 int8을 사용하면 모델의 크기가 1/4로 줄어들고, 추론(inference) 속도와 메모리 사용량도 두 배에서 네 배까지 효율적으로 작동하게 됩니다.
- 모델 크기 4배 감소
- 메모리 대역폭 2~4배 감소: 32비트에서 8비트로 이동해서, 메모리가 4배 감소
- 메모리 대역폭 절약 및 int8 산술을 통한 더 빠른 계산으로 인해 2~4배 더 빠른 추론이 가능(정확한 속도 향상은 하드웨어, 런타임 및 모델에 따라 달라짐)
양자화 종류

Post Training Quantization (PTQ)
모델을 training한 후에 quantize를 적용하는 기법
파라미터 사이즈가 큰 모델에서 정확도 하락 폭이 작으며 파라미터 사이즈가 작은 소형 모델에는 적합하지 않음
모델의 파라미터가 작을수록, quantization에 따라 모델이 예민하게 반응하기 때문에 정확도 감소가 크게 일어나게 됨
- Dynamic Quantization
- Static Quantization
장점
- 파라미터 크기가 큰 대형 모델에 대해서 정확도 하락폭이 작다
단점
- 파라미터 크기가 작은 소형 모델에 대해서는 정확도 하락폭이 크다.
Quantization Aware Training (QAT)
모델 training 과정중에서 quantize를 수행
Fake quantization node를 첨가하여 quantize되었을 시 어떻게 동작할지 시뮬레이션 실행
장점
- 모델 사이즈 축소 (저장 용량 효율화)
- RAM 메모리 bandwidth 절약
- 추론 속도 개선
- 전력 소비 효율화
- 다른 양자화 보다 높은 정확도를 가짐 (모델의 정확도 감소 폭을 최소화할 수 있음, 소형 모델에도 적용 가능)
단점
- 모델 정확도가 저하됨
- 모델 학습 이후 추가 연산(양자화)가 필요
Quantization 기법 소개
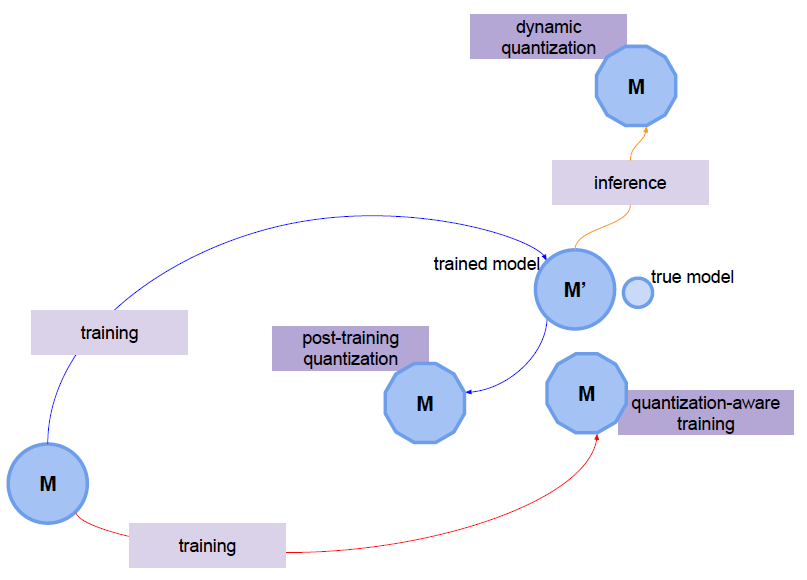
Dynamic Quantization (동적 양자화)
- 가장 간단한 양자화 기법
- 모델의 가중치(weight)에 대해서만 양자화 진행
- 활성화(activiation)은 추론할 때 동적으로 양자화
- 모델을 메모리에 로딩하는 속도 개선
- 연산속도 향상 효과 미비(inference kernel 연산이 필요하기 때문에)
- CPU 환경에서만 inference 가능(프레임워크나 프레임워크의 버전에 따라 GPU 환경에서도 동작할 순 있음)
- 모델의 weight를 메모리에 로딩하는 것이 실행 시간에 큰 영향을 미치는 BERT와 같은 모델에 적합
Static Quantization (정적 양자화)
- 모델의 가중치와 활성화(activiation)모두 사전에 양자화를 진행
- 연산속도 향상
- 활성화가 inference에 영향이 큰 CNN 모델에 적합
Quantization Aware Training
- 모델의 가중치와 활성화를 학습하면서 양자화
- Dynamic, Static Quantization 보다 높은 accuracy 확보 가능
- 학습은 CPU, GPU 환경에서 사용 가능 / inference는 CPU에서만 가능
- dynamic, static quantization으로 성능이 나오지 않는 CNN 모델에서 활용
** 양자화 기법을 선택할 때는 모델의 성능과 메모리/연산 요구 사항 등을 고려하여 적절한 기법을 선택하는 것이 중요합니다.
| 양자화 기법 | 설명 |
| Dynamic Quantization | 미리 학습된 모델의 가중치와 활성화 함수의 비트 수를 줄이는 기법 런타임 시 양자화되며, 가중치와 활성화 함수의 분포에 따라 크기가 다양하게 조절 인퍼런스 중 성능 저하가 덜 발생하며, 변환 비용이 낮음 |
| Static Quantization | 훈련 후, 가중치와 활성화 함수의 비트 수를 줄이는 기법 가중치와 활성화 함수의 분포를 분석하여 고정된 양자화 스케일과 오프셋을 결정하고 모델을 양자화 인퍼런스 시 성능 저하가 발생할 수 있음 |
| Quantization Aware Training(QAT) | 훈련 중에 양자화를 고려하여 모델을 조정하는 방법 가중치 양자화에 대한 학습을 포함하여 원본 모델을 보다 양자화에 robust하게 만듦 일반적으로 인퍼런스 시 성능 저하가 적음 |
GPTQ: Accurate Post-training Quantization of Generative Pretrained Transformers
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Generative Pre-trained Transformer models, known as GPT or OPT, set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs. Specifically, due to their mass
arxiv.org
Github: https://github.com/IST-DASLab/gptq
GitHub - IST-DASLab/gptq: Code for the ICLR 2023 paper "GPTQ: Accurate Post-training Quantization of Generative Pretrained Trans
Code for the ICLR 2023 paper "GPTQ: Accurate Post-training Quantization of Generative Pretrained Transformers". - IST-DASLab/gptq
github.com
References
'Generative AI > Language Model' 카테고리의 다른 글
| LlamIndex (라마인덱스) (4) | 2024.09.12 |
|---|---|
| [Metrics] ROUGE score, text 생성 타스크 평가 지표 (0) | 2023.08.07 |
| [Large Language Model] Hallucination (환각) (0) | 2023.08.03 |
| Risks of Large Language Models (대규모 언어 모델의 위험) (0) | 2023.08.03 |
| [LLM] 업스테이지 모델, ‘허깅페이스 오픈 LLM 리더보드’서 세계 1위 (0) | 2023.08.02 |