ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
https://aclanthology.org/W04-1013/
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin. Text Summarization Branches Out. 2004.
aclanthology.org
ROUGE는 텍스트 자동 요약, 기계 번역 등 자연어 생성 모델의 성능을 평가하기 위한 지표이며, 모델이 생성한 요약본 혹은 번역본을 사람이 미리 만들어 놓은 참조본과 대조해 성능 점수를 계산합니다.

ROUGE는 n-gram recall을 계산하며, 정답 문장의 n-gram이 생성 문장에 얼마나 포함되는지의 비율을 의미합니다.
Recall은 참조 요약본을 구성하는 단어 중 몇 개의 단어가 시스템 요약본의 단어들과 겹치는지를 보는 점수입니다.
참고: 머신러닝 성능 평가 지표들
[Model Performance Measure] Precision, Recall, Accuracy, F1 score, FPR, ROC curve, AUC
Precision(정밀도)
모델의 예측값이 얼마나 정확하게 예측됐는가를 나타내는 지표
PPV(Positive Predictive Value), Positive 정답률이라고도 불림
ex) 날씨 예측 모델이 맑다고 예측했는데, 실제 날씨가 맑았는지를 살펴보는 지표

- 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
- 시스템이 올바르게 예측한 엔티티 수를 시스템이 예측한 수로 나눈 값
Recall(재현율)
실제값 중에서 모델이 검출한 실제값의 비율을 나타내는 지표
통계학에서는 sensitivity로 다른 분야에서는 hit rate라는 용어로도 사용
ex) 암환자들이 병원에 갔을 때 암환자라고 예측될 확률을 구하는 것

- 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
- 시스템이 올바르게 예측한 개체수를 주석을 단 사람이 직접 식별한 수로 나눈 값
Precision vs Recall
Precision이나 Recall은 모두 실제 True인 정답을 모델이 True라고 예측한 경우에 관심이 있으나, 바라보는 관점은 다르다.
Precision은 모델의 입장에서, Recall은 실제 정답(data)의 입장에서 정답을 정답이라고 맞춘 경우를 바라본다.
ROUGE-N, ROUGE-S, ROUGE-L은 요약본의 일정 부분을 비교하는 성능 지표입니다.
예를 들어, ROUGE-1은 시스템 요약본과 참조 요약본 간 겹치는 unigram의 수를 보는 지표이며, ROUGE-2는 시스템 요약본과 참조 요약본 간 겹치는 bigram의 수를 보는 지표입니다.
시스템 요약 (모델 생성 요약): the cat was found under the bed
참조 요약 (Gold standard, 대개 사람이 직접 만든 요약): the cat was under the bed
ROUGE-1: unigram


ROUGE-2: bigram
시스템 요약 (bigrams): the cat, cat was, was found, found under, under the, the bed
참조 요약 (bigrams): the cat, cat was, was under, under the, the bed
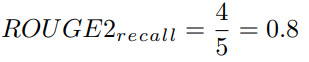

Precision은 시스템 요약본 중 67%의 bigram이 참조 요약본 내 bigram과 겹친다는 것을 의미합니다
기타 ROUGE 지표들
ROUGE-N
unigram, bigram, trigram 등 문장 간 중복되는 n-gram을 비교하는 지표입니다.
ROUGE-L
LCS (Longest Common Subsequence)기법을 이용해 최장 길이로 매칭되는 문자열을 측정합니다.
LCS의 장점은 ROUGE-2와 같이 단어들의 연속적 매칭을 요구하지 않고, 어떻게든 문자열 내에서 발생하는 매칭을 측정하기 때문에 보다 유연한 성능 비교가 가능하다는 것입니다.
Reference: police killed the gunman
System-1: police kill the gunman
System-2: the gunman kill police
ROUGE-N: System-1 = System-2 (“police”, “the gunman”)
ROUGE-L:
- System-1 = 3/4 (“police the gunman”)
- System-2 = 2/4 (“the gunman”)
ROUGE-S
특정 Window size가 주어졌을 때, Window size 내에 위치하는 단어쌍들을 묶어 해당 단어쌍들이 얼마나 중복되게 나타나는 지를 측정합니다. 때문에 해당 기법을 Skip-gram Co-ocurrence 기법이라 부르기도 합니다.
예를 들어, Skip-bigram은 최대 2칸 내에 존재하는 단어들을 쌍으로 묶어, 해당 쌍들이 참조 문장과 생성 문장 간 얼마나 중복되는게 나타나는지를 측정합니다.
e.g.) “cat in the hat”
해당 문장에서 발생할 수 있는 Skip-bigram은 “cat in”, “cat the”, “cat hat”, “in the”, “in hat”, “the hat”이 됩니다.
BLEU: n-gram precision
ROUGE(n-gram recall)만 고려할 경우 평가지표가 정확하지 않을 수도 있다.
만약에, 모델이 생성했던 시스템 요약본이 엄청나게 긴 문장이었을 경우 참조 요약본과 크게 관련이 없을지라도 참조 요약본의 단어 대부분을 포함할 가능성이 커지게 되기 때문입니다.
이러한 문제를 해결하기 위해 우리는 Precision을 계산할 필요가 있습니다.
Precision은 Recall과 반대로 모델이 생성한 시스템 요약본 중 참조 요약본과 겹치는 단어들이 얼마나 많이 존재하는지를 의미합니다.

ROUGE-1, BLUE 계산 예시
시스템 요약 (모델 생성 요약): the cat was found under the bed
참조 요약 (Gold standard, 대개 사람이 직접 만든 요약): the cat was under the bed
시스템 요약 2: the tiny little cat was found under the big funny bed

모델이 생성한 시스템 요약 문장 내에 불필요한 단어가 너무 많이 존재하기 때문에 좋은 점수를 받을 수 없게 됩니다.
간결한 요약문을 생성해내야 하는 상황에서 Precision은 아주 좋은 성능 지표로 사용될 수 있습니다
상황에 따라, 정확한 모델 성능 평가는 지표들의 조합으로 판단하는 것이 좋을 수 있습니다.
정확한 모델의 성능 평가를 위해서는 Precision과 Recall을 모두 계산한 후, F-Measure(F1-Score, Precision(정밀도)와 Recall(재현율)의 조화 평균)를 측정하는 것이 좋을 수 있습니다.
만약에 모델의 제약 조건으로 인해 간결한 요약 만을 생성한다면, Recall(ROUGE)만 사용해도 괜찮을 수 있습니다.
(이 경우, Precision은 성능 평가에 크게 중요하게 고려되지 않습니다.)
결론적으로,
다양한 ROUGE 성능 지표들 중 어떠한 지표를 사용할 것인지는 평가하고자 하는 모델의 태스크에 달려있습니다
References
'Generative AI > Language Model' 카테고리의 다른 글
| LlamIndex (라마인덱스) (4) | 2024.09.12 |
|---|---|
| Model Quantization (양자화) (0) | 2024.04.09 |
| [Large Language Model] Hallucination (환각) (0) | 2023.08.03 |
| Risks of Large Language Models (대규모 언어 모델의 위험) (0) | 2023.08.03 |
| [LLM] 업스테이지 모델, ‘허깅페이스 오픈 LLM 리더보드’서 세계 1위 (0) | 2023.08.02 |