Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
ChatGPT 및 그 이상에 대한 설문조사에 관한 내용을 정리하였습니다.
https://arxiv.org/abs/2304.13712
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
This paper presents a comprehensive and practical guide for practitioners and end-users working with Large Language Models (LLMs) in their downstream natural language processing (NLP) tasks. We provide discussions and insights into the usage of LLMs from t
arxiv.org
이 문서는 자연어 처리(NLP) downstream 작업에서 대규모 언어 모델(Large Language Model, LLM)로 작업하는 실무자와 최종 사용자를 위한 포괄적이고 실용적인 가이드를 제공합니다.
https://github.com/Mooler0410/LLMsPracticalGuide
GitHub - Mooler0410/LLMsPracticalGuide: A curated list of practical guide resources of LLMs (LLMs Tree, Examples, Papers)
A curated list of practical guide resources of LLMs (LLMs Tree, Examples, Papers) - GitHub - Mooler0410/LLMsPracticalGuide: A curated list of practical guide resources of LLMs (LLMs Tree, Examples,...
github.com
다음의 주요 가이드를 포함합니다.
- Natural language understanding: 분산 데이터가 없거나 교육 데이터가 거의 없는 경우 LLM의 탁월한 일반화 기능을 사용합니다.
- Natural language generation.:LLM의 기능을 활용하여 다양한 애플리케이션을 위한 일관되고 상황에 맞는 고품질 텍스트를 생성합니다.
- Knowledge-intensive tasks(기술 집약적 작업): 도메인별 전문 지식 또는 일반적인 세계 지식이 필요한 작업을 위해 LLM에 저장된 광범위한 지식을 활용합니다.
- Reasoning ability(추론 능력): LLM의 추론 기능을 이해하고 활용하여 다양한 상황에서 의사 결정 및 문제 해결을 개선합니다.
The evolutionary tree of modern LLMs
다음은 대규모 언어 모델(Large Language Model, LLM) 진화 트리(Evoluation Tree)입니다.
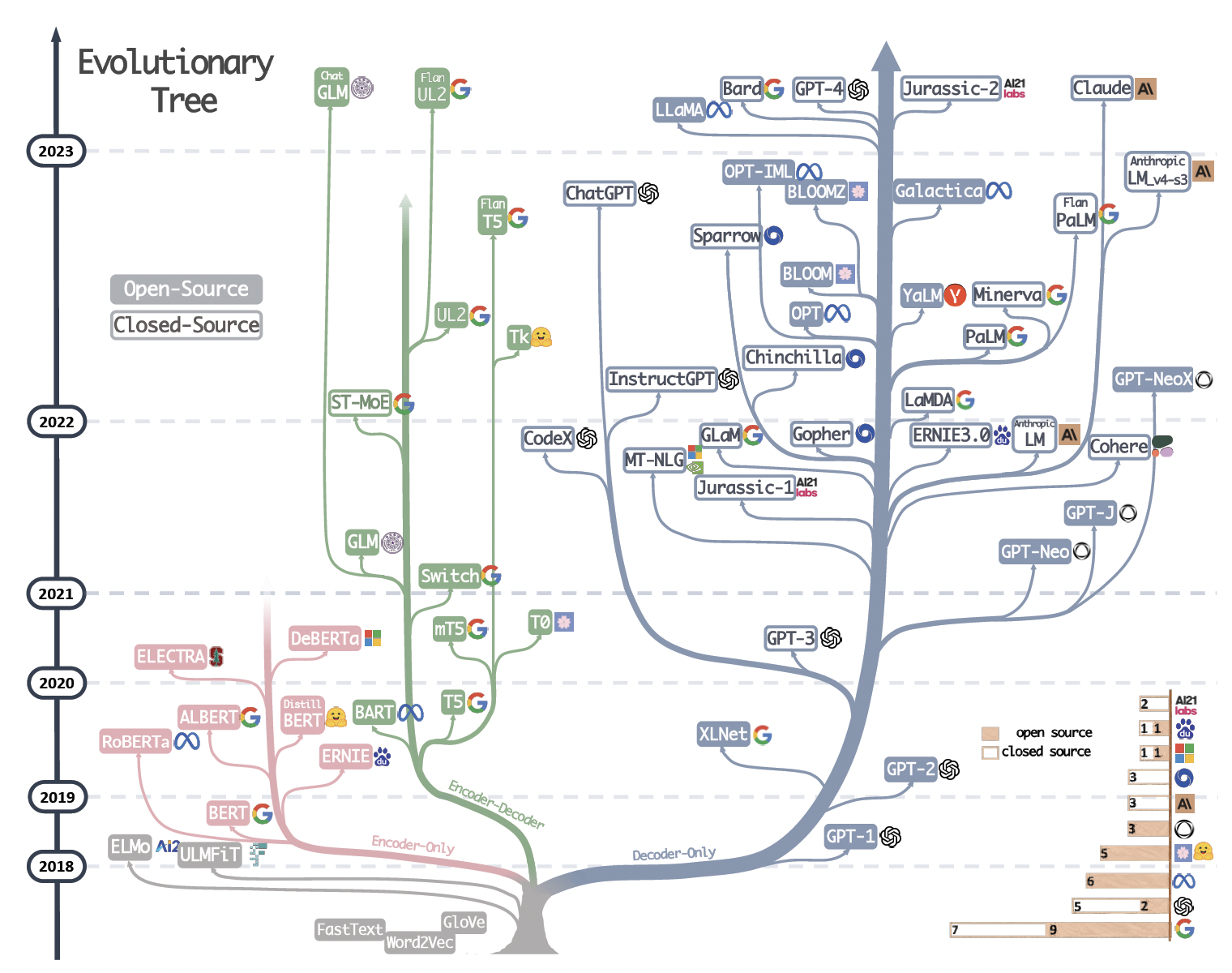
같은 분기에 있는 모델은 더 밀접한 관계를 가집니다.
- Transformer-based models: non-grey color
- Decoder-only model:s blue branch
- Encoder-only models: pink branch
- Encoder-Decoder models: green branch
타임라인에서 모델의 세로 위치는 출시 날짜를 나타냅니다.
오픈 소스 모델은 속이 꽉 찬 사각형으로, 비 오픈소스(유료) 모델은 속이 빈 사각형으로 표시됩니다.
오른쪽 하단의 누적 막대 그래프는 다양한 회사 및 기관의 모델 수를 보여줍니다.
메타가 개발한 초거대언어모델은 모두 오픈소스이며, OpenAI의 ChatGPT 이후 모델들은 아직 다 비 오픈소스(유료)입니다.
인코더-디코더 모델은 아키텍처가 여전히 활발하게 탐색되고 있고 대부분이 오픈 소스이기 때문에 여전히 유망합니다. Google은 오픈 소스 인코더-디코더 아키텍처에 상당한 기여를 했습니다. 그러나 디코더 전용 모델의 유연성과 다양성으로 인해 이 방향에 대한 Google의 주장이 덜 유망해 보입니다.
| Characteristic | LLMs | |
| Encoder-Decoder or Encoder-only (BERT-style) |
Training: Masked Language Models Model Type: Discriminative Pretrain task: Predict masked words |
ELMo, BERT, RoBERTa, DistilBERT, BioBERT, XLM, Xlnet, ALBERT, ELCTRA, T5, GLM. XLM-E, ST-MoE, AlexaTM |
| Decoder-only (GPT-style) |
Training: Autoregressive Language Models Model Type: Generative Pretrain task: Predict next word |
GPT-3, OPT, PaLM, BLOOM, MT-NLG, GLaM, Gopher, chinchilla, LaMDA, GPT-J, LLaMA, GPT-4, BloombergGPT |
BERT-style Language Models: Encoder-Decoder or Encoder-only
Masked Language Models
motivates the unsupervised learning of natural language
주변 컨텍스트를 고려하면서 문장에서 마스킹된 단어를 예측하는 방식입니다.
모델은 단어와 단어가 사용되는 컨텍스트 간의 관계를 더 깊이 이해할 수 있습니다.
Transformer 아키텍처와 같은 기술을 사용하여 대규모 텍스트 코퍼스에서 훈련을 해서, 감정분석 및 엔터티 인식과 같은 많은 NLP 작업에서 최점단 결과를 달성했습니다.
주요 모델은 BERT, RoBERTa, T5 등이 있습니다.
T5: [NLP][Language Model] T5(Text-to-Text Transfer Transformer)
GPT-style Language Models: Decoder-only
Autoregressive Language Models
언어 모델은 일반적으로 아키텍처에서 작업에 구애받지 않지만 이러한 방법은 특정 다운스트림 작업의 데이터 세트에 대한 미세 조정이 필요합니다.
연구자들은 언어 모델을 확장하면 few-shot, 심지어 zero-shot 성능도 크게 향상된다는 사실을 발견했습니다.
더 나은 few-shot 및 zero-shot 성능을 위한 가장 성공적인 모델은 이전 단어가 주어진 시퀀스에서 다음 단어를 생성하여 학습되는 자동 회귀 언어 모델(Autoregressive Language Models)입니다. 이러한 모델은 텍스트 생성 및 질문 답변과 같은 다운스트림 작업에 널리 사용되었습니다.
자동 회귀 언어 모델의 예로는 GPT-3, OPT, PaLM 및 BLOOM이 있습니다. 게임 체인저인 GPT-3는 처음으로 프롬프팅 및 컨텍스트 내 학습(in-context learning)을 통해 합리적인 few/zero shot 성능을 보여 자기 회귀 언어 모델의 우수성을 보여주었습니다.
금융 도메인을 위한 BloombergGPT, 코드 생성과 같은 특정 작업에 최적화된 CodeX와 같은 모델도 있습니다.
최근의 돌파구는 ChatGPT로, 특히 대화 작업을 위해 GPT-3를 개선하여 다양한 실제 응용 프로그램을 위한 대화형, 일관성 및 상황 인식 대화를 제공합니다.
'Generative AI > Language Model' 카테고리의 다른 글
| [Large Language Model] BLOOM (0) | 2023.07.11 |
|---|---|
| [Large Language Model] FLAN-T5 (0) | 2023.07.11 |
| [Foundation Model] GPT-4 / GPT-3 (0) | 2023.04.12 |
| [NLP] Language Model이란 (0) | 2023.03.12 |
| [Language Model] BERT (0) | 2022.05.09 |