나이브 베이즈 (Naïve Bayes)
나이브 베이즈 분류 알고리즘은 데이터를 나이브(단순)하게 독립적인 사건으로 가정하고, 이 독립 사건들을 베이즈 이론에 대입시켜 가장 높은 확률의 레이블로 분류를 실행하는 알고리즘
Bayes' theorem (베이즈 정리)
어떤 사건이 서로 배반하는 원인 둘에 의해 일어난다고 할 때 실제 사건이 일어났을 때 이것이 두 원인 중 하나일 확률을 구하는 정리
조건부 확률(사후 확률)을 구하는 것을 말하며, 어떤 사건이 일어난 상황에서, 그 사건이 일어난 후 앞으로 일어나게 될 다른 사건의 가능성을 구하는 것.
즉, 기존 사건들의 확률(사전 확률)을 알고 있다면, 어떤 사건 이후의 각 원인들의 조건부 확률을 알 수 있다
단, 기존 사건들의 확률을 알지 못하다면 베이즈 정리는 쓸모없는 것이 되는 한계가 있다.
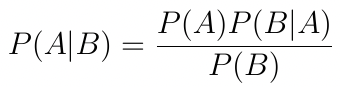
P(A|B): 어떤 사건 B가 일어났을 때 사건 A가 일어날 확률
P(B|A): 어떤 사건 A가 일어났을 때 사건 B가 일어날 확률
P(A): 어떤 사건 A가 일어날 확률

두 사건 A와 B가 독립사건이라면,


P(A∩B) = P(A|B)P(B) = P(B∩A) = P(B|A)P(A)
A와 B가 독립시행일 경우 P(A∩B) = P(A)*P(B)

P(B) = P(B∩A)
= P(B∩A1) + P(B∩A2)
= P(B|A1)P(A1) + P(B|A2)P(A2)

P(레이블 | 데이터 특징) = P(데이터 특징 | 레이블) * P(레이블) / P(데이터 특징)
가우시안 나이브 베이즈
특징들의 값들이 정규 분포(가우시안 분포)돼 있다는 가정하에 조건부 확률을 계산
연속적인 성질이 있는 특징이 있는 데이터를 분류하는데 적합
다항 분포 나이브 베이즈(Multinominal Naïve Bayes)
데이터의 특징이 출현 횟수로 표현됐을 때 사용
예, 주사위를 10번 던졌을 때
1이 한번, 2가 두 번, 3이 세번, 4가 네 번 나왔을 경우, 주사위를 10번 던진 결과 데이터를 (1,2,3,4,0,0)과 같이 표현
데이터의 출현 횟수에 따라 값을 달리한 데이터에 사용
베르누이 나이브 베이즈(Bernoulli Naïve Bayes)
데이터의 특징이 0 또는 1로 표현됐을 떄 사용
예, 주사위를 10번 던졌을 떄
1이 한번, 2가 두 번, 3이 세번, 4가 네 번 나왔을 경우, 주사위를 10번 던진 결과 데이터를 (1,1,1,1,0,0)과 같이 표현
데이터의 출현 여부에 따라 1 또는 0으로 구분됐을 때 사용
스무딩(Smoothing)
이산적인 데이터의 경우 빈도수가 0인 경우가 발생
학습 데이터에 없던 데이터가 출현해도 빈도수에 1을 더해서 확률이 0이 되는 현상을 방지
나이브 베이즈(Naïve Bayes)의 장점과 단점
장점
- 모든 데이터의 특징이 독립적인 사건이라는 가정에도 부구하고 실전에서 높은 정확도를 보임
- 문서 분류 및 스팸 메일 분류에 강함
- 나이브 가정에 의해 계산 속도가 다른 모델들에 비해 빠름
단점
- 모든 데이터의 특징을 독립적인 사건이라고 가정하는 것은 문서 분류에 적합할지는 모르나 다른 분류 모델에는 제약이 될 수 있음
References
'Machine Learning > Supervised Learning' 카테고리의 다른 글
| [Supervised Learning][Ensemble][Bagging] Random Forest (0) | 2022.10.06 |
|---|---|
| [Machine Learning][Regression Metrics] R-squared(결정계수) (0) | 2022.10.05 |
| [Supervised Learning][Regression] Ridge Regression, Lasso Regression (0) | 2022.09.27 |
| [Supervised Learning][Classification] SVM(Support Vector Machine) (0) | 2021.03.24 |
| [Supervised Learning] Ensemble (0) | 2021.03.24 |