Distilling the Knowledge in a Neural Network
논문링크: https://arxiv.org/abs/1503.02531
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome
arxiv.org
Knowledge Distillation 방법은 앙상블된 지식을 압축해 단일 모델로 증류함으로써
앙상블 방식으로 모델을 훈련할 때 많은 계산비용이 발생하는 상황에 대한 대안을 제시합니다.
Background
Neural Network의 오버피팅을 피하기 위해 앙상블 기법이 사용됩니다.
앙상블은 여러 모델을 사용하여 계산 시간이 많이 걸리는 단점이 있어, 앙상블만큼의 성능을 갖되 '적은 파라미터 수'를 가진 Neural Network 모델이 필요하여 대안으로 제시되었습니다.
Knowledge Distillation
화학에서 액체를 가열하여 생긴 기체를 냉각하여 다시 액체로 만드는 것을 증류(distillation)라고 부르는데, 이러한 개념을 Neural Network에 사용한 것을 의미합니다.
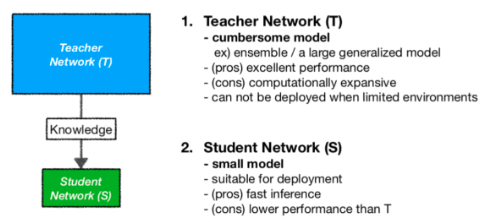
Neural Network에서 지식 증류(Knowledge Distillation)는 큰 모델(techer network)로부터 증류한 지식을 작은 모델(student network)로 transfer하는 과정입니다.
즉, 한번 훈련된 대규모 머신러닝(혹은 모델)의 "지식"을 소비자들에게 배포하기 적합한 작은 모델에 증류하는 방법을 제안합니다.
How to Knowledge Distillation
네트워크의 지식을 일반적으로 각 훈련된 네트워크의 파라미터들이 아닌 단순히 네트워크를 거쳐서 나온 출력 벡터를 지식으로 생각한다면 지식을 증류한다는 개념이 쉽게 와 닿을 수 있습니다.

지식을 증류할 때, 큰 모델과 작은 모델은 같은 데이터셋을 사용합니다.
큰 모델의 일반화 능력을 작은 모델에 전수하는 방법은, 복잡한 모델의 클래스 확률을 사용하여 작은 모델을 훈련하는 'soft targets'을 사용합니다.
높은 엔트로피의 'soft targets'을 사용하면 'hart targets'를 사용할 때보다 더 많은 정보를 제공받을 수 있습니다.

soft label: large model의 softmax output([0.1, 0.1, 0.7, 0.1])
hard label: 기존 one hot encoding 방식 output([0,0,1,0])
Teacher Network 학습
Student Network 학습
Student Network soft prediction + Teacher Network soft label을 통해 distillation loss 구성
Student Network hard prediction + Original hard label을 통해 student loss 구성
Teacher 모델의 손실값과 Student 모델의 Cross entropy 값을 더해 갱신해나는 것.
단계)
1. Teacher Network: training set(x, hard label)을 사용해 large model 학습
2. large model 학습 뒤, large model의 output(soft label)을 target으로 하는 transfer set(x, soft label)을 생성.
이때, soft labe의 T는 1이 아닌 높은 값 사용
3. Student Network
transfer set을 사용해 small model 학습: T는 soft label을 생성할 때와 같은 값 사용. soft predictions
transfer set을 사용해 small model 학습: T는 1로 고정. hart predictions
4. loss 생성
distillation loss: soft label과 soft predictions의 차이를 Kullback-Leiber Divergence를 통해 구함
student loss: hart predictions와 hard label을 Cross-entropy를 통해 구함
5. 두 loss를 더해서 최종 loss를 구함
References
- https://dsbook.tistory.com/324
- https://velog.io/@ahp2025/Distilling-the-Knowledge-in-a-Neural-Network-논문-리뷰
'NLP > NLP 기초' 카테고리의 다른 글
| [NLP] Natural Language Processing (자연어 처리) (1) | 2023.03.07 |
|---|---|
| PII (Personally Identifiable Information, 개인 식별 정보) (0) | 2022.12.13 |
| [NLP] NLP Dataset (0) | 2021.06.11 |
| [NLP] Gensim (0) | 2021.04.11 |
| [NLP] 자연어 처리를 위한 수학 (0) | 2021.04.11 |