HDBSCAN(Hierarchical Density-Based Spatial Clustering)
https://hdbscan.readthedocs.io/en/latest/index.html
The hdbscan Clustering Library — hdbscan 0.8.1 documentation
© Copyright 2016, Leland McInnes, John Healy, Steve Astels Revision 109797c7.
hdbscan.readthedocs.io
DBSCAN
- DBSCAN은 하이퍼파라미터로 최소 클러스터 사이즈(MinPts)와 밀도 거리인 threshold epsilon(ε)을 지정해야 한다.
- DBSCAN의 결과는 모델의 hyper-parameter인 ε과 MinPts에 따라 상당히 다른 결과를 보여준다.
- DBSCAN의 local density에 대한 정보를 반영할 수 없고, 데이터들의 계층적 구조를 반영한 clustering 불가능하다.
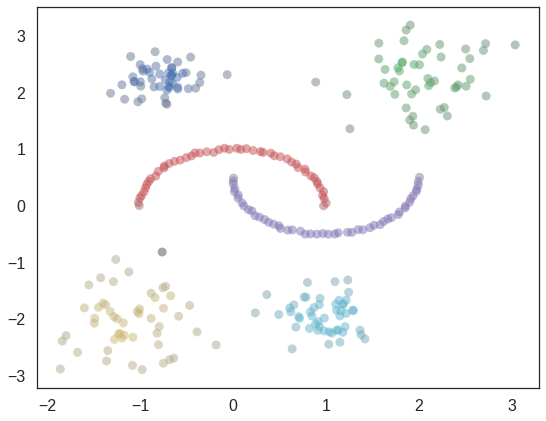
HDBSCAN은 DBSCAN과 계층(Hierarchical)적 군집분석 개념을 통합한 기법
HDBSCAN은 (가변의 밀도를 가진 클러스터를 찾는 방법) 다양한 epsilon값을 기반으로 실행시키기 때문에 최소 클러스터 사이즈(MinPts)만 사용자가 지정해 주면 된다.
HDBSCAN의 한계
- HDBSCAN이 항상 DBSCAN보다 좋은 결과를 보장하는 것은 아니다.
- HDBSCAN의 결과 너무 세분화된 클러스터가 도출될 수도 있다.
- 최소 epsilon을 사용자가 정하는 것이 유효성을 설명할 수 있을 때가 있다.
--> min_cluster_size을 이용하여 최소점을 정할 수 있다.
HDBSCAN Hyper parameters
min_cluster_size
- mutual reachability distance와 condensed tree 구성에 영향을 미치는 가장 직관적인 파라미터
min_samples
- 높은 값을 줄수록 더 많은 점들이 noise로 분류됨 (최종 클러스터 선정 시 constraint로 작용)
cluster_selection_epsilon
- DBSCAN 알고리즘을 적용할 최대 거리 명시
HDBSCAN 단계
1. Transform the space (Density space 생성)
Transform the space according to the density/sparsity
dataset의 값들을 density/sparsity 의미를 포함한 값으로 변환함
- core distance of point x for parameter k, core_k(x): 점 x에서 k개의 min_cluster_size를 만족시키는 거리
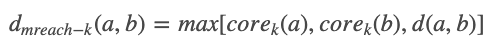
- mutual reachability distance of point a and b: 두 점 a와 b의 거리를 잴 때 {1. a의 이웃과의 거리, 2. b의 이웃과의 거리, 3. a와b 자체의 거리} 중 max값을 고르는 것.
- noise point에 의해서 서로 멀리 떨어진 클러스터가 하나로 묶이는 것을 방지하고자 각 점의 sparsity를 반영한 mutual reachability distance를 거리 지표로 사용

2. Build the MST(Minimum Spanning Tree)
Build the minimum spanning tree of the distance weighted graph
point간의 mutual reachability distance값을 기반으로 MST(minimum spanning tree)를 만듦
데이터를 각 꼭지점으로 삼으며 잇되, 그 이은 선(edge)에 점수(mutual reachability)를 부여
distance가 weight인 graph(길이가 길수록 weight도 커짐)로 만드는 것
트리의 적합은 아직 추가되지 않은 점 중 가장 가까운(가장 점수가 낮은) edge를 하나씩만 추가하며, 결과적으로 모든 점을 포괄할 때까지 트리를 키워나간다.
모든 점들 간 거리를 계산하는 것은 비용이 너무 크므로 Prim's algorithm 을 통해 최소의 tree만 구성
※ Prim's algorithm: 매순간 총 edge의 길이를 최소화하는 점을 이어가며 모든 점을 잇는 greedy algorithm

3. Construct a cluster hierarchy
Construct a cluster hierarchy of connected components
connected component들의 클러스터 hierarchy를 구축함
- minimal spanning tree를 hierarchy of connected components로 변환
- 일반 hierarchical 클러스터링과 동일한 원리로 진행
mutual reachability (혹은 weight)를 점차 낮추면서, 하나씩 graph를 끊는다.
그 후 만들어진 minimum spanning tree를 가장 가까운 거리부터 묶는다.

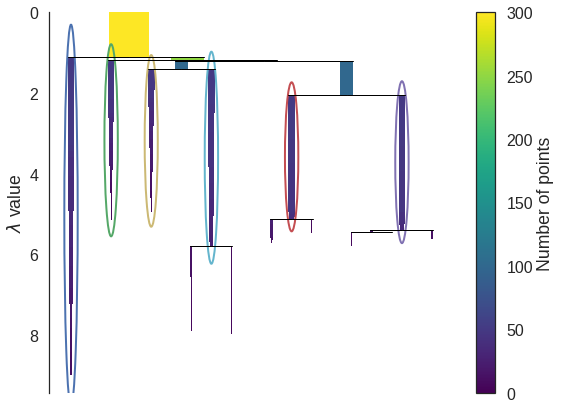
4. Condense the cluster hierarchy
Condense the cluster hierarchy based on minimum cluster size
설정된 MinPts값을 기반으로 클러스터 hierarchy를 축약함
- min_cluster_size 파라미터를 활용하여 hierarchy의 각 노드를 더 합쳐가며 smaller tree를 만듦
- 만약 tree의 split points 중 하나라도 min_cluster_size 미만의 점을 가지고 있다면 합친다.
그래프의 선의 너비는 그 component에 포함된 데이터 수를 의미한다.

5. Extract the clusters
Extract the stable clusters from the condensed tree
축약된 클러스터 hierarchy에서 stable한 클러스터만 선택함
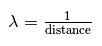
위 식을 활용하여 각 cluster의 persistence를 나타냄
각 cluster의 stability는 cluster를 구성하는 점들의 람다를 더한 값으로 표현
만약 child cluster의 stability가 더 높다면, parent cluster의 stability는 child clusters의 합으로 표현
References
- https://heave.tistory.com/60
- https://teamdable.github.io/techblog/Unsupervised-hdbscan
- Go's BLOG-HDBSCAN
'Machine Learning > Unsupervised Learning' 카테고리의 다른 글
| [Unsupervised Learning] [Clustering] Agglomerative Clustering(병합 군집) (0) | 2022.10.05 |
|---|---|
| [Unsupervised Learning] Clustering (0) | 2022.10.05 |
| [Unsupervised Learning][Clustering] Mean Shift (평균 이동) (1) | 2022.10.05 |
| [Unsupervised Learning][Clustering] K-means (K 평균) (0) | 2022.10.04 |
| [Unsupervised Learning][Clustering] DBSCAN (0) | 2021.06.14 |