spaCy
spaCy · Industrial-strength Natural Language Processing in Python
spaCy is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
spacy.io
파이썬의 자연어 처리를 위한 오픈 소스 기반 라이브러리
텍스트 전처리에서 좋은 성능을 보여주고 있음
spacy install
pip install spacy
# download en stopwords
python -m spacy download en
python -m spacy download en_core_web_sm
Language Processing Pipelines

spaCy 강점
1) (독립적인 연구에 의하면) 세계에서 가장 빠르고,
2) 사용하기 쉬워서 빠르게 자연어처리를 할 수 있고,
3) 딥러닝 프레임워크와 호환이 잘되기 때문에, 매우 범용적이다.
Fastest in the world
spaCy excels at large-scale information extraction tasks. It’s written from the ground up in carefully memory-managed Cython. Independent research has confirmed that spaCy is the fastest in the world. If your application needs to process entire web dumps, spaCy is the library you want to be using.
Get things done
spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It’s easy to install, and its API is simple and productive. We like to think of spaCy as the Ruby on Rails of Natural Language Processing.
Deep learning
spaCy is the best way to prepare text for deep learning. It interoperates seamlessly with TensorFlow, PyTorch, scikit-learn, Gensim and the rest of Python’s awesome AI ecosystem. With spaCy, you can easily construct linguistically sophisticated statistical models for a variety of NLP problems.
POS Tagging
- Text: The original word text.
- Lemma: The base form of the word.
- POS: The simple part-of-speech tag.
- Tag: The detailed part-of-speech tag.
- Dep: Syntactic dependency, i.e. the relation between tokens.
- Shape: The word shape — capitalization, punctuation, digits.
- is alpha: Is the token an alpha character?
- is stop: Is the token part of a stop list, i.e. the most common words of the language?
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp('Natural Language Processing Test')
print(type(doc)) ## 타입은, Doc고,
print(doc) ## 그냥 출력하면, 원래 문장
print(list(doc)) ## 리스트로 변형하면, tokenize한 결과
print(type(doc[0])) ## 리스트의 가장 앞에 있는 값은 Token이라는 타입Visualization
displayCy 라이브러리를 이용하여 문장 성분들간의 관계를 시각화
import spacy
from spacy import displacy
doc = nlp("This is a sentence")
displacy.serve(doc, style="dep")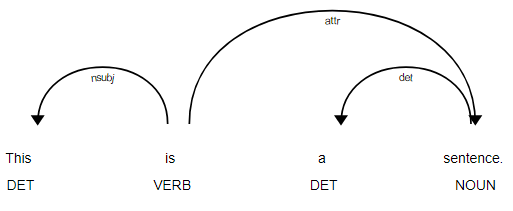
entity recognizer를 시각화해서 표현
import spacy
from spacy import displacy
text = """
When Sebastian Thrun started working on self-driving cars at Google in 2007,
few people outside of the company took him seriously.
"""
nlp = spacy.load("custom_ner_model")
doc = nlp(text)
displacy.serve(doc, style="ent")
References
'NLP > NLTK' 카테고리의 다른 글
| [NLP] NLTK(Natural Language Toolkit) (0) | 2021.03.10 |
|---|