728x90
반응형
구문 분석(Syntactic Analysis)
- 자연어 문장에서 구성 요소들의 문법적 구조를 분석하는 기술
- 문법적 구조 정보를 자동으로 추출
- 기계 번역, 정보 검색, 전문가 시스템에서 문장 의미의 분석을 돕는 세부 기술로 활용
목표
- 자연어 문장의 문법적 구조를 구문 문법에 따라 자동으로 분석하는 것
규칙 기반 구문 분석
- 인간이 직접 정의한 문법 규칙을 적용하여 구문 분석을 수행하는 접근 방법
장점
- 미리 정의된 문법 규칙을 적용할 수 있는 문장에 대해서는 정확한 의존 분석이 가능
한계
- 적용할 문법 규칙을 미리 정의하기 위한 시간과 비용 문제 발생
- 언어학에 대한 전문성을 가진 노동력이 요구
- 수동으로 정의되지 않은 문법 규칙에 대해서는 구문 분석 불가능
- 자연어 중의성 처리 문제 발생
통계 기반 구문 분석
- 확률적인 문법 규칙을 통계적으로 계산하여 구문 분석을 수행하는 접근 방법
장점
- 구문 중의성을 작는 문장에서도 여러 구분 분석 결과 각각의 확률을 계산한 뒤 가장 타당할 것으로 예상되는 구문 분석 결과 선택
한계
- 구문 분석 과정에서 요구되는 언어적 정보를 충분히 활용 못함
딥러닝 기반 구문 분석
- 인간이 구축한 구문 분석 데이터셋으로부터 딥러닝 모델을 학습하여 구문 분석을 수행하는 접근 방법
장점
- 딥러닝 모델을 학습하여 자연어 문장에 포함된 여러 정보를 활용할 수 있음
- 문장 전체 구조 정보, 어휘의 하위 범주화 정보 등을 특징 벡터의 계산에 반영하여 구문 분석 활용 가능
한계
- 학습 결과가 대량의 실수 파라미터들로나타나므로 학습한 문법 규칙과 구문 분석 결과이 근거가 해석 불가능
구문 문법(contrcution Grammar)
- 언어학에서 문법적 구성 요소들로부터 문장을 생성하고, 반대로 문장을 구성 요소로들로 분석하는 문법
| 구문 문법 | Pharase Structure Grammar(구구조 문법) | Dependency Grammar(의존 문법) |
| 제안자 | Noam Chomsky(노암 촘스키)가 제안 | Lucien Tesniere(뤼시앵 테니에르)가 제안 |
| 설명 | 자연어 문장을 하위 구성소들로 나눔으로써 문장 구조를 나타내는 문법 구성소 관계(consitituency relation)에 기반하여 문장 구조를 분석 단어들이 모여 절을 구성하며 이러한 절과 단어들의 계층적 관계에 다라 문장이 이루어진다고 분석 |
의존 관계(dependency relation)에 기반하여 문장 구조를 분석 문장을 구성하는 단어들 간의 계층적인 의존 관계에 따라 문장이 이루어진다고 분석 |
| 예시 그림 |  |
|
구문 중의성(Syntax Ambiguity)
- 자연어 문장의 구문 구조가 다양한 방식으로 분석될 수 있는 특징
Remember in prayer the many who are sick of our church and community
- Remember in prayer [[the many] [who are sick of our church and community]].
- Remember in prayer [[the many] [who are sick] of our church and community].
구구조 구문 분석(Phrase Structure Parsing)
- 구구조 문법에 기반한 구문 분석 기술
- 단어들과 이들이 모여 구성한 절의 계층적 관계에 따라 문장 구조를 분석
규칙 기반 구구조 구문 분석
- 인간이 가지고 있는 언어학적 지식을 컴퓨터가 이해할 수 있는 형태의 문법 규칙으로 미리 정의한 뒤 이를 자연어 문장에 정의함으로써 구문 분석을 구행
- Phrase Structure Grammar: 자연어 문장을 하위 구성소들로 나눔으로써 문장 구조를 나타내는 문법
구성소(Constituency)
- 한 개의 단위같이 기능하는 일련의 단어들
- 계층 구조 내에서 단일 단위로 기능하는 단어 또는 단어 그룹
CYK 알고리즘(Cocke-Younger-Kasami Algorithm)
- 모든 문맥 자유 문법을 파싱할 수 있는 가장 효율적인 알고리즘
통계 기반 구구조 구문 분석
- 통계적으로 확률적 구구조 문법을 계산하여 이를 바탕으로 구문 분석을 수행하는 접근 방법
- 확률적 구구조 문법(Probabilistic Phrase Structure Grammar)
구구조 문법 규칙을 계산하는 방법
- 인간이 직접 태깅한 구구조 구문 분석 코퍼스로부터 각 규칙이 나타나는 조건부 확률을 계산
- 태깅되지 않은 자연어 문자들에 구구조 구문 분석을 수행하여 문법 규칙들의 조건부 확률을 조정
- 자연어 문장에 대하여 가능한 여러 구문 분석 트리 중 분석 결과의 전체 확률이 가장 높은 것을 구문 분석 결과로 제시
Inside-Outside 알고리즘
- 확률적 문법 규칙을 계산하는 대표적인 알고리즘
딥러닝 기반 구구조 구문 분석
- 인간이 구축한 구구조 구문 분석 데이터셋으로부터 딥러닝 모델을 학습하여 구문 분석을 수행하는 접근 방법
- 딥러닝 모델
- 자연어 문장의 표층 정보와 의미적 정보를 입력으로 하여 구성소들의 구조를 예측
Transition-based Parsing(전이 기반 파싱)
- 자연어 문장을 한 단어씩 읽으며 현재 단계에서 수행할 액션을 선택하는 방식으로 문장 전체의 구구조 구문 분석을 수행하는 방법
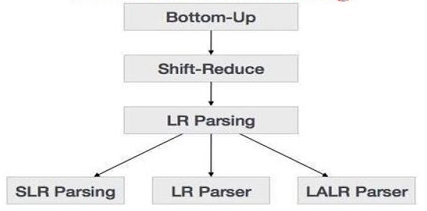
Shift-redude Parsing
- shift(이동), unary-reduce(단항 감축), binary-reduce(이항 감축)으로 구성
- 이동 연산: 자연어 문장에 포함된 단어를 순차적으로 스택에 이동
- 감축 연산: 스택에 저장된 하나 또는 두 개의 구성소를 꺼내 상위 구성소로 감축한 뒤 이 상위 구성소를 다시 스택에 이동
- 액션의 선택은 오라클(Oracle)이 결정
딥러닝 전이 기반 파싱
- 오라클이 RNN 인코더로 계산한 자연어 문장 및 각 단어의 특징 벡터, 스택의 현재 상태 등을 입력으로 받는 딥러닝 모델
의존 구문 분석(Dependency Structure Parsing)
- 문장에서 단어 간의 의존 관계를 분석함으로써 문장 전체의 문법적 구조를 분석하는 기술
- 단어 간의 의존 관계와 그 유형을 분석함으로써 문장의 문법적 구조를 적합하게 표현하는 의존 분석 트리를 구축
한국어 의존 구문 분석에서 사용되는 규칙
- 한국어는 지배소 후의 언어. 지배소는 피지배소보다 항상 뒤에 위치
- 교차 의존 구조는 없다
- 각 어절의 머리는 유일하다(=각 어절의 지배소는 하나)
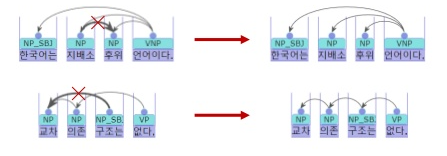
규칙 및 통계 기반 의존 구문 분석
규칙 기반 의존 구문 분석
- 의존 문법의 형태로 문법 규칙을 저장한 뒤 이를 적용함으로써 의존 구문 분석 수행
- 의존 문법: 자연어 문장에서 단어 간이 의존 관계를 표현하는 구문 문법
- Head(지배소): 절의 중심이 되는 단어
- Modifier(의존소): 지배소에 의존하는 단어
CG(Constraint Grammar)
- 규칙 기반 의존 구문 분석을 위한 문맥 의존 규칙을 정의하는 문법
통계적 의존 구문 분석
- 문맥 의존 규칙의 조건부 확률을 통계적으로 계산하여 의존 구문 분석에 적용
딥러닝 기반 의존 구문 분석
- 인간이 구축한 의존 구문 분석 데이터셋으로부터 딥러닝 모델을 학습하여 구문 분석을 수행하는 접근 방법
Transition-based Parsing
- 자연어 문장에 포함된 단어를 하나씩 의존 분석 트리에 포함시킴으로써 의존 구문 분석을 수행하는 방식
- 액션 선택에서 지역적인 정보에 국한
Graph-based Parsing
- 자연어 문장에 포함된 단어 간의 가능한 의존 관계에 대한 점수(score)를 계산한 뒤, 문장 전체에서 가장 높은 점수를 갖는 의존 분석 트리를 선택하는 의존 분석 방법
- 장점
- 가능한 모든 의존 분석 트리 중 가장 높은 점수를 갖는 것을 선택함으로써 문장 전체의 문법적 구조를 고려할 수 있음
- 단점
- 유효한 최적의 의존 분석 트리 구축을 위한 시간복잡도가 높아 실사용 단계에서 비효율성이 발생할 수 있음
References
728x90
반응형
'NLP > NLP 기초' 카테고리의 다른 글
| [NLP] 자연어 처리를 위한 수학 (0) | 2021.04.11 |
|---|---|
| [NLP] Semantic Analysis (0) | 2021.04.05 |
| [NLP] Lexical Analysis (0) | 2021.04.05 |
| [NLP] 언어학의 기본 원리 (0) | 2021.04.05 |
| [NLP] Corpus (0) | 2021.04.05 |